📌 TL;DR
Batch processing is predictable, manageable, and completely wrong for fraud detection. This article covers how adding Kafka to the platform transforms agents from scheduled batch processors into reactive event-driven systems — the difference between catching fraud after the fact and catching it as it unfolds.
⏮️ Previous: Governing with Intelligence: OPA Policies and Agent-Driven Compliance → | ⏭️ Next: Documentation as Code: Making Your Agentic Platform Self-Describing →
📖 In This Article
- The Case Against Batch-Only Processing
- Three Topics, Three Concerns
- Publishing Transactions: Where Producer Config Matters
- Change Data Capture: Downstream Reactivity Without Polling
- Streaming Ingestion: When Kafka Is the Source
- Event-Driven Agent Triggers: The Real Payoff
- Consumer Groups: Scaling Without Coordination Code
- Observability: Consumer Lag Is the Signal
- Schema Evolution Without Coordination
- Key Takeaways
⏱️ The Case Against Batch-Only Processing
Here is a scenario I have seen play out in real financial platforms: a fraudulent card transaction happens at 14:03. The batch job runs at 18:00. By the time the platform processes the transaction, four hours have passed — and so has the fraud window. The period during which the card issuer could have blocked follow-on transactions, notified the customer, and triggered enhanced verification is gone.
This is not a hypothetical risk. It is the operating assumption baked into every batch-only financial platform: we will always know about fraud after it has succeeded.
Two more failure modes worth naming. MiFID II (the EU Markets in Financial Instruments Directive, which governs transaction reporting for financial instruments) has same-day reporting obligations for certain transaction types. An overnight batch job literally cannot satisfy an intraday regulatory deadline. And compliance agents that monitor AML patterns need to act on data as it arrives — an agent consuming batch outputs cannot detect a suspicious pattern that spans three transactions when two of them arrived in the current batch and one arrived in the previous one, already filed.
Streaming does not replace batch processing. It adds a real-time path alongside it, so time-sensitive processing does not wait for the batch window.
↑ Back to top · Next: Three Topics, Three Concerns →
📨 Three Topics, Three Concerns
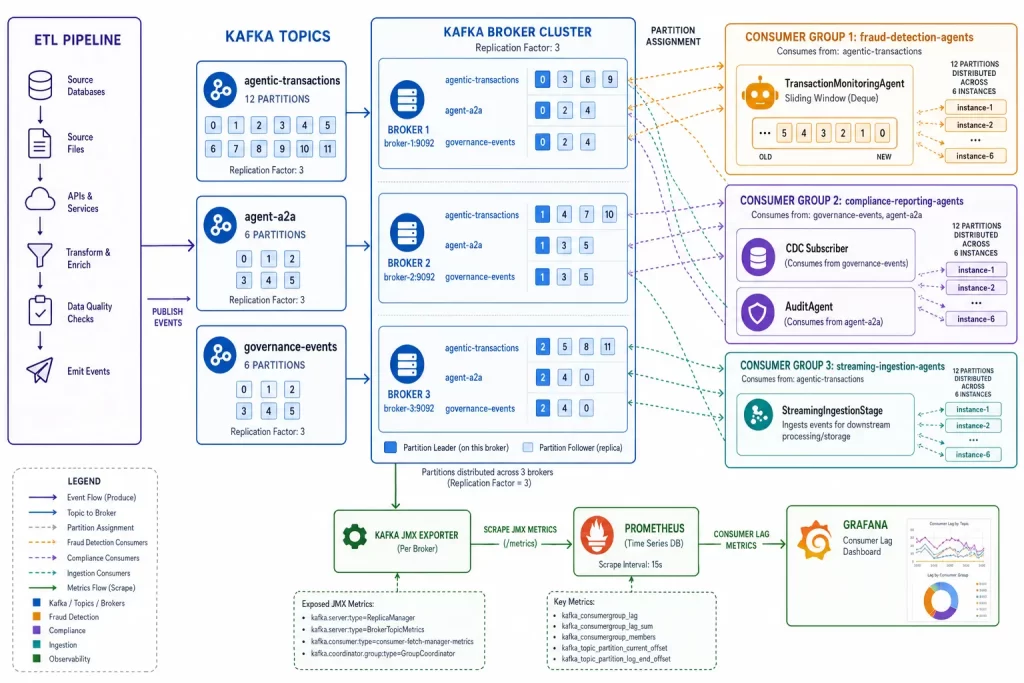
The platform uses three Kafka topics, each serving a distinct architectural purpose:
agentic-transactions — processed transaction events from the ETL pipeline
agent-a2a — agent-to-agent messages (covered in Part 12)
governance-events — OPA policy decisions and compliance eventsApache Kafka is a distributed event streaming platform built around the concept of an immutable, append-only log. Producers write events to named topics; consumers read from those topics at their own pace, independently, without affecting other consumers. Topics are divided into partitions — ordered, numbered sub-logs — which enable parallel processing and horizontal scaling.
Mixing transaction events and governance events in a single topic is a tempting shortcut. Resist it. Every consumer would need to filter out events it doesn’t care about — adding code complexity and CPU overhead for no benefit. The rule of one topic per event type keeps consumers simple and makes it possible to set different retention policies per topic (short for governance noise, long for audit-critical transactions).
The agentic-transactions topic is configured with 12 partitions — enough to support twelve parallel consumers at peak load. In production, replication factor is 3, meaning Kafka maintains two follower copies of every partition. The platform can lose two brokers simultaneously and continue processing without data loss.
↑ Back to top · Next: Publishing Transactions: Where Producer Config Matters →
📤 Publishing Transactions: Where Producer Config Matters
The KafkaPublishStage sits at the end of the ETL pipeline and publishes each processed transaction as a Kafka event. The interesting part is not what it publishes — it is the producer configuration:
producer = KafkaProducer(
bootstrap_servers=self.bootstrap_servers,
value_serializer=lambda v: json.dumps(v).encode("utf-8"),
acks="all",
retries=3,
retry_backoff_ms=100,
)
# ...
producer.send(self.topic, value=payload)
producer.flush()acks="all" is the non-negotiable setting for financial data. It means the producer waits for acknowledgement from every in-sync replica before considering a message delivered. Without it — with acks=1 (leader only) — a message is considered sent the moment the partition leader writes it. If that leader fails before replicating to its followers, the message is gone. For a fraud detection system, that lost message could be the exact transaction that completes a suspicious pattern.
producer.flush() before the stage returns is equally important. Kafka’s producer batches messages internally for throughput. Calling flush() forces everything buffered to be sent. Skip it, and a process exit mid-batch silently drops the last few messages.
The stage handles ImportError gracefully — if kafka-python is not installed, it logs a warning and skips publication. This makes Kafka genuinely optional in development: the pipeline runs identically with or without it, and Kafka is promoted to mandatory in production via the stage tags mechanism covered in Part 3.
↑ Back to top · Next: Change Data Capture: Downstream Reactivity Without Polling →
🔄 Change Data Capture: Downstream Reactivity Without Polling
The CDCTrackingStage publishes a structured change event to a separate agentic-cdc-events topic every time the pipeline commits a batch to the database:
cdc_event = {
"event_type": "INSERT",
"table": "staged_data",
"batch_id": batch_id,
"record_count": len(transactions),
"timestamp": datetime.now().isoformat(),
"schema_version": "1.0",
}
producer.send(self.cdc_topic, value=cdc_event)Change Data Capture (CDC) is the pattern of publishing an event every time a database record is created, updated, or deleted — turning a mutable data store into a stream of changes that downstream systems can consume. The conventional alternative is polling: a downstream service queries SELECT * FROM staged_data WHERE updated_at > :last_checked every N seconds. CDC eliminates that query load entirely and reduces latency from N seconds to milliseconds.
For this platform, CDC events are what let a downstream analytics service maintain a real-time materialized view without querying the operational database. They are also what lets the AuditAgent (covered in Part 6) subscribe to database changes and immediately check whether the inbound batch looks suspicious — without waiting for a batch job to surface the data to it.
↑ Back to top · Next: Streaming Ingestion: When Kafka Is the Source →
📥 Streaming Ingestion: When Kafka Is the Source
The StreamingIngestionStage flips the data flow direction — instead of the pipeline producing to Kafka, this stage consumes from it. It is used for real-time processing scenarios where external systems publish transactions to agentic-transactions and the platform processes them as a continuous stream:
consumer = KafkaConsumer(
self.topic,
bootstrap_servers=self.bootstrap_servers,
group_id="streaming-ingestion",
auto_offset_reset="latest",
enable_auto_commit=True,
)
for message in consumer:
if elapsed_seconds >= self.duration:
break
scrubbed_memo = self.scrubber.scrub_memo(message.value.get("memo", ""))
self._ingest_record(message.value, scrubbed_memo, pipeline_context)auto_offset_reset="latest" means the consumer starts from the newest messages, ignoring historical backlog. For a fraud detection agent that only needs to act on new transactions, this is correct. For a compliance reporting agent that needs to process everything since midnight, "earliest" is correct. The choice is not technical preference — it is regulatory obligation. Getting it wrong means either missing current transactions or reprocessing already-reported ones.
enable_auto_commit=True has a subtle failure mode worth naming: if the consumer crashes after reading a message but before processing it, Kafka will not know it was not processed — the offset was already committed. For idempotent downstream operations (writing to a database with upsert semantics), this is acceptable. For non-idempotent operations, manual offset commit after successful processing is safer.
↑ Back to top · Next: Event-Driven Agent Triggers: The Real Payoff →
⚡ Event-Driven Agent Triggers: The Real Payoff
The most powerful capability streaming enables is agents that react to individual events rather than processing batches. A TransactionMonitoringAgent subscribes to the topic and maintains a sliding window of recent activity:
class TransactionMonitoringAgent:
def __init__(self):
self.window = deque(maxlen=100)
def process_transaction(self, transaction: dict) -> None:
self.window.append(transaction)
if len(self.window) >= 10:
anomaly = self.anomaly_detector.check_window(list(self.window))
if anomaly:
self.alert_callback(severity="warning", ...)deque(maxlen=100) is Python’s double-ended queue with a fixed capacity. When the 101st item is added, the oldest drops off automatically. This is the sliding window pattern: the agent always sees the last 100 transactions, regardless of how long it has been running. It is a one-liner that replaces what would otherwise be manual index management and list slicing.
The business impact of this architecture is not subtle. The window check runs as each transaction arrives from Kafka — within milliseconds of the ETL pipeline publishing it. Compare that to a batch agent that processes the same data six hours later. The fraudulent pattern that spans transactions 97, 98, 99, and 100 in the window gets caught in real time. In a batch world, by the time those four transactions appear in the same dataset, three of them may have already cleared.
↑ Back to top · Next: Consumer Groups: Scaling Without Coordination Code →
📈 Consumer Groups: Scaling Without Coordination Code
Kafka’s consumer group mechanism solves the scale problem without requiring any application-level coordination. When multiple agent instances share the same group_id, Kafka automatically assigns partitions across them:
consumer = KafkaConsumer(
"agentic-transactions",
group_id="fraud-detection-agents",
# ...
)With 12 partitions and 6 consumer instances: 2 partitions per instance. Scale to 12 instances: 1 partition per instance, maximum parallelism. A 13th instance sits idle — you cannot have more active consumers than partitions. This is why partition count is set to 12 at topic creation time: it sets the ceiling for how far the consumer group can scale.
When an instance fails, Kafka detects the missing heartbeat and rebalances — redistributing its partitions among the surviving consumers. The surviving consumers pick up from the last committed offset. No data is lost; no manual intervention is needed. This is the operational reason to use consumer groups even for single-instance deployments: adding the second instance later requires no code change.
↑ Back to top · Next: Observability: Consumer Lag Is the Signal →
📊 Observability: Consumer Lag Is the Signal
For streaming systems, the metric that matters most is consumer lag — how many messages have been produced to a topic that the consumer has not yet processed. Rising lag means the consumer is falling behind. For fraud detection, rising lag means delayed responses. For compliance reporting, rising lag means missed deadlines.
The platform scrapes Kafka’s JMX metrics via Prometheus:
- job_name: kafka
static_configs:
- targets: ["kafka:9101"] # Kafka JMX exporter endpointThe Grafana dashboard plots lag per consumer group and partition. An alert fires when lag in fraud-detection-agents exceeds a configurable threshold — not when the consumer errors, but before it reaches a failure state. Lag is a leading indicator; errors are a lagging one.
↑ Back to top · Next: Schema Evolution Without Coordination →
🔀 Schema Evolution Without Coordination
Financial data schemas change. New transaction types appear. Fields are renamed. The platform handles this with a schema_version field on every message.
Consumers use schema_version to select the correct deserialization path. Producers always write the latest version. Old versions are supported for the Kafka retention window (7 days by default). This gives all consumers time to deploy updated deserialization logic before old-format messages expire.
For teams that need stronger guarantees — preventing a producer from publishing a schema that would break existing consumers — a Confluent Schema Registry with Avro or Protobuf schemas enforces compatibility at publish time. The current JSON approach trades that safety for simplicity; both are valid choices depending on how many independent teams are producing and consuming the same topics.
🙏 Thank You, Reader
Thank you for working through the streaming layer. The shift from batch to event-driven is not just a technical upgrade — it changes what your platform can guarantee to regulators and what it can catch in time to matter. The configurations here are small, but the failure modes they prevent are not.
Part 1 : From Scripts to Sentience: Building an Agentic Data Platform
Part 2 : Engineering the Foundation: A Production-Grade Development Environment
Part 3 : Designing for Intelligence: The Agentic Data Pipeline Architecture
Part 4 : Synthetic Data Engineering: Teaching Your Platform What Real Data Looks Like
Part 5 : Building the Engine: Core ETL Stages with Agent Instrumentation
📫 Connect With Me
- 💼 LinkedIn: Connect with me on LinkedIn
- 💻 GitHub
↑ Back to top · Next: Key Takeaways →
🔑 Key Takeaways
acks="all"is non-negotiable for financial Kafka producers — anything less risks silent message loss on broker failure.- Topic-per-event-type keeps consumers simple and enables different retention and replication policies per concern.
- Change Data Capture (CDC) events let downstream systems react to database changes in milliseconds instead of polling on a schedule.
- Consumer groups scale to partition count — set partition counts for target load, not current load.
- Consumer lag is the primary health signal for streaming components; alert on lag before it becomes errors.
Enjoyed this article?
Get notified when the next one is published.
We send one email per new article — no spam, unsubscribe any time.
⚠️ Disclaimer: The information provided on LearnWithNeeraj.com regarding Astrology, Numerology, and other topics is for educational and guidance purposes only.
Not Professional Advice: This content should not be used as a substitute for professional medical, legal, or financial advice. Always consult a certified professional for specific concerns.
Guest Authors: This site features articles by various contributors. The views and interpretations expressed are those of the individual authors and do not necessarily reflect the views of the website administrator.
Your destiny is in your hands. Use this information as a map, not a mandate.