📌 TL;DR
Before building a pipeline, you need data to run through it. For a financial data platform operating under GDPR and SOX, using real customer data in development and testing is not just inadvisable — it is illegal without explicit consent and extensive controls. Synthetic data is the answer. This article explains how the platform generates realistic financial transaction data that preserves the statistical properties of real data without containing actual personal information, and how an agentic layer monitors for drift between synthetic and production data distributions.
⏮️ Previous: Designing for Intelligence: The Agentic Data Pipeline Architecture → | ⏭️ Next: Building the Engine: Core ETL Stages with Agent Instrumentation →
Part 1 : From Scripts to Sentience: Building an Agentic Data Platform
Part 2 : Engineering the Foundation: A Production-Grade Development Environment
📖 In This Article
🚨 The Synthetic Data Imperative
Every data platform needs data to test with. The naive approach — copying a sample from the production database — violates GDPR‘s data minimisation principle (Article 5(1)(c)), which requires that personal data only be collected and used to the minimum extent necessary for the stated purpose. Development and testing is not the stated purpose for which transaction data was collected.
Beyond GDPR, copying production data to a development environment creates a SOX (Sarbanes-Oxley Act) audit finding: SOX Section 404 requires strict controls over financial data, and moving it to an uncontrolled environment breaks the chain of custody.
Synthetic data solves both problems cleanly. If the generated data contains no actual personal information, GDPR data minimisation is satisfied. If it never leaves the development environment, SOX controls are maintained. The challenge is making it realistic enough to be useful — a dataset of random numbers in the right numeric range won’t expose edge cases in currency validation logic or trigger the governance engine’s threshold checks.
↑ Back to top · Next: The Transaction Data Model →
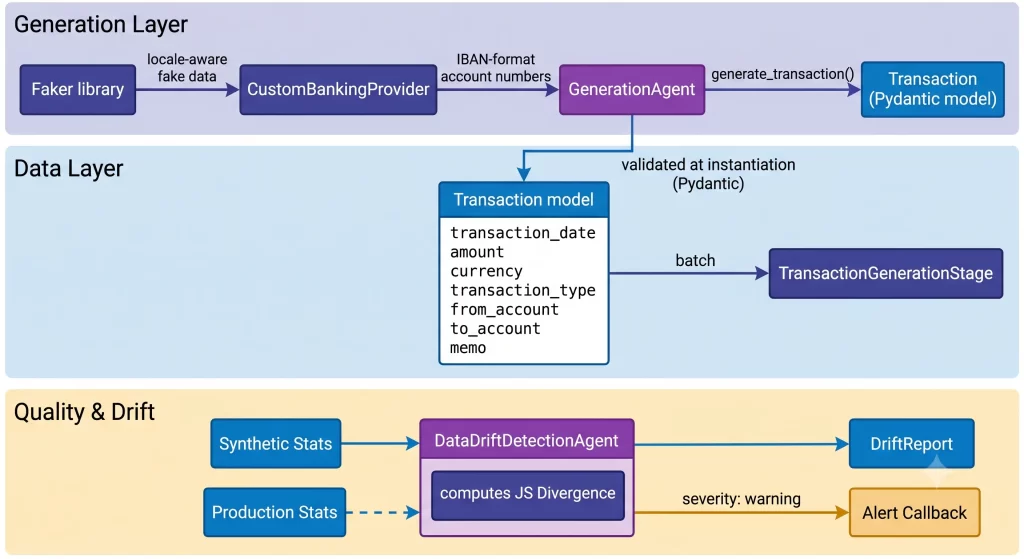
📐 The Transaction Data Model
The Transaction Pydantic model is the contract that the generator and the pipeline share:
class Transaction(BaseModel):
transaction_date: date
amount: float
currency: str # ISO 4217 code — validated downstream
transaction_type: str # Must match a registered type from config
from_account: Optional[str]
to_account: Optional[str]
memo: str # Free text — intentionally contains synthetic PIIPydantic validates types at instantiation. If the generator produces a malformed record (wrong type for amount, missing memo), it fails immediately — before the record enters the pipeline. This is a deliberate choice: catch generation bugs at the source, not halfway through a 50-stage pipeline run.
The memo field carries the most complexity. Real financial memos mix natural language with structured identifiers — names, account references, amounts. Generating realistic memo text that exercises the PII scrubber without containing real personal data is the core challenge of the synthetic data problem.
↑ Back to top · Next: The Generation Architecture →
⚙️ The Generation Architecture
The GenerationAgent combines the Faker library (for locale-aware fake data) with domain-specific memo templates:
class GenerationAgent:
def __init__(self):
self.fake = Faker(DEFAULT_LOCALE)
self.fake.add_provider(CustomBankingProvider) # IBAN-format account numbers
def generate_transaction(self) -> Transaction:
trans_type = random.choice(TRANSACTION_TYPES)
memo, amount, from_acc, to_acc = self._build_memo(trans_type)
return Transaction(
transaction_date=self.fake.date_this_year(),
amount=amount,
currency=DEFAULT_CURRENCY,
transaction_type=trans_type,
from_account=from_acc,
to_account=to_acc,
memo=memo,
)Faker is a Python library for generating realistic fake data — names, addresses, phone numbers, IBANs — in any of dozens of locales. The CustomBankingProvider extends it with domain-specific identifiers like structured account numbers in the format the platform expects. The separation of concerns is important here: Faker handles personal data simulation; the custom provider handles financial identifiers; the template layer combines them into a coherent memo string.
↑ Back to top · Next: Transaction Types and Amount Distributions →
📊 Transaction Types and Amount Distributions
The platform is configured with four transaction types, each with its own amount distribution:
TRANSACTION_TYPES = ["salary", "financing_contract", "transfer", "payment"]
AMOUNT_RANGES = {
"salary": (3_000, 15_000), # Monthly payroll
"financing_contract": (50_000, 500_000), # Structured, high-value
"transfer": (100, 10_000), # Peer-to-peer
"payment": (50, 5_000), # Merchant transactions
}These ranges are not arbitrary — they mirror the statistical shape of real-world financial data, where salary payments cluster in a narrow mid-range, structured financing transactions are infrequent but high-value, and merchant payments are frequent and low-value. This matters because governance rules depend on amount thresholds: a policy that triggers enhanced due diligence above a certain amount needs test data that exercises both sides of that threshold. Evenly distributed random amounts would rarely hit the boundary conditions that expose policy bugs.
Both TRANSACTION_TYPES and AMOUNT_RANGES are configurable via environment variables. A team building a wholesale payments platform configures different types. A Southeast Asian deployment configures different currencies and locale. The generator adapts without code changes.
↑ Back to top · Next: Memo Generation: The Hard Part →
✍️ Memo Generation: The Hard Part
Each transaction type has a memo template that combines Faker-generated personal data with structured financial identifiers:
def _build_memo(self, transaction_type: str) -> tuple:
template = MEMO_TEMPLATES[transaction_type]
# e.g. "Salary payment to {name} ID {national_id}, account {iban}. Amount: {currency} {amount}."
amount = round(random.uniform(*AMOUNT_RANGES[transaction_type]), 2)
memo = template.format(
name=self.fake.name(), # "Jane Doe" — synthetic, not real
national_id=self.fake.numerify("##########"),
iban=self.fake.iban(),
currency=DEFAULT_CURRENCY,
amount=amount,
)
return memo, amount, ACCOUNT_NAMES.get(transaction_type), self.fake.iban()The resulting memo is structurally indistinguishable from a real financial memo — it contains a recognisable name pattern, an IBAN-format account number, and a national ID number. But none of these values correspond to any real person. Synthetic PII is not fake in the sense of being obviously wrong; it is structurally realistic without being personally identifiable.
↑ Back to top · Next: Intentional PII: Why the Generator Includes It →
🔐 Intentional PII: Why the Generator Includes It
Counterintuitively, the generator deliberately puts PII-like content in every memo. This is a design decision, not a bug.
The PIIScrubberStage is a critical compliance component. If synthetic memos contained no PII, the scrubber would never trigger during testing, and the platform could ship a pipeline with an entirely untested compliance control. By generating memos that always contain a name, an IBAN, and an ID number, every test run exercises the scrubber, validates its output (the scrubbed memo must not contain [PERSON] or [ID] entities in their original form), and confirms that the compliance component is working before the data reaches storage.
This is a testing principle worth internalising: test data should exercise the safety controls, not avoid them.
↑ Back to top · Next: Controlled Scenario Data →
🧪 Controlled Scenario Data
Random generation covers general pipeline testing. Specific edge cases need controlled data. A ScenarioDataFactory provides named datasets for the test suite:
class ScenarioDataFactory:
@staticmethod
def high_value_batch(size: int = 10) -> list[Transaction]:
"""All transactions above the governance threshold — tests enhanced due diligence rules."""
gen = GenerationAgent()
txs = []
while len(txs) < size:
tx = gen.generate_transaction()
if tx.amount > HIGH_VALUE_THRESHOLD:
txs.append(tx)
return txs
@staticmethod
def invalid_currency_batch(size: int = 5) -> list[Transaction]:
"""Invalid ISO 4217 currency codes — tests schema validation rejection."""
txs = [GenerationAgent().generate_transaction() for _ in range(size)]
for tx in txs:
tx.currency = "XXX" # Not a valid ISO 4217 code
return txs
# ... similar factories for negative amounts, future-dated records, missing memosThese factories serve a dual purpose. They are test utilities that produce the exact data profile needed to exercise a specific code path. And they are living documentation of every edge case the pipeline is designed to handle — which is genuinely useful when onboarding a new engineer who needs to understand what the governance and validation stages actually protect against.
↑ Back to top · Next: Agentic Drift Detection →
📡 Agentic Drift Detection
Synthetic data is generated to approximate real data at a point in time. But production data evolves — seasonal patterns shift, new transaction types appear, amount distributions change as the business grows. If the synthetic data doesn’t keep pace, tests will pass against data that no longer represents what the pipeline will see in production.
This is the synthetic-to-production drift problem. The platform addresses it with a DataDriftDetectionAgent that runs periodically:
class DataDriftDetectionAgent:
def check_distribution_drift(self, synthetic_stats, production_stats) -> DriftReport:
divergence = self._compute_js_divergence(
synthetic_stats["amount_distribution"],
production_stats["amount_distribution"],
)
if divergence > self.threshold:
self.alert_callback(
severity="warning",
message=f"Synthetic data drift detected (JS divergence: {divergence:.3f})",
source="DataDriftDetectionAgent",
details={"divergence": divergence, "threshold": self.threshold},
)
return DriftReport(divergence=divergence, exceeded=divergence > self.threshold)Jensen-Shannon divergence is a statistical measure of the difference between two probability distributions. A value of 0 means the distributions are identical; a value approaching 1 means they are completely different. The configurable threshold (default: 0.15) determines how much drift is acceptable before an alert is raised. When the agent fires, the data platform team can update the AMOUNT_RANGES configuration to better match the current production distribution — no code change required.
This closes the feedback loop between synthetic data quality and production accuracy, which would otherwise go unnoticed until a test that should have caught a production bug passes because the test data no longer reflects production reality.
↑ Back to top · Next: Integration With the Pipeline →
🔌 Integration With the Pipeline
The TransactionGenerationStage wraps GenerationAgent and plugs it into the pipeline stage interface:
class TransactionGenerationStage(PipelineStage):
def execute(self, data, pipeline_context):
batch_size, _ = data
transactions = self.generator.generate_batch(batch_size)
pipeline_context["transactions"] = transactions
return transactions, [""] * len(transactions) # empty memos slot for PIIScrubberIn production, this stage is replaced by a real ingestion stage that reads from the upstream data source. Everything downstream — validation, governance evaluation, PII scrubbing, lineage capture — is identical in both cases. The source of data is completely decoupled from its processing, which is the core value of the stage-based architecture.
↑ Back to top · Next: Key Takeaways →
🔑 Key Takeaways
- Synthetic data is the compliant solution — using real production data in development violates GDPR data minimisation and SOX custody controls; it is not just inconvenient, it is illegal without explicit consent and extensive controls.
- Statistical realism is non-negotiable — synthetic data must replicate the statistical properties of real data to be useful: distributions, proportions, and boundary conditions that trigger governance rules.
- Test data must exercise safety controls — intentionally including synthetic PII in memo fields ensures the
PIIScrubberStageis exercised in every test run; data that avoids the scrubber leaves a critical compliance control untested. - Scenario factories are living specifications — a
ScenarioDataFactory.high_value_batch()call is both a test utility and a specification of what the governance engine must handle, making edge cases reproducible and self-documenting. - Drift detection closes the feedback loop — the
DataDriftDetectionAgentuses Jensen-Shannon divergence to alert when synthetic distributions diverge from production, preventing tests from passing against data that no longer reflects reality.
🙏 Thank You, Reader
Thank you for reading. Synthetic data engineering is one of those foundational decisions that shapes everything downstream — from how quickly you can iterate in development to how confidently you can claim your compliance controls actually work. If this article helped clarify the why behind the design choices, the next article digs into the core ETL stages that process the data this generator produces.
📫 Connect With Me
- 💼 LinkedIn: Connect with me on LinkedIn
- 💻 GitHub
Enjoyed this article?
Get notified when the next one is published.
We send one email per new article — no spam, unsubscribe any time.
⚠️ Disclaimer: The information provided on LearnWithNeeraj.com regarding Astrology, Numerology, and other topics is for educational and guidance purposes only.
Not Professional Advice: This content should not be used as a substitute for professional medical, legal, or financial advice. Always consult a certified professional for specific concerns.
Guest Authors: This site features articles by various contributors. The views and interpretations expressed are those of the individual authors and do not necessarily reflect the views of the website administrator.
Your destiny is in your hands. Use this information as a map, not a mandate.