📌 TL;DR
With the architecture designed and synthetic data ready, this article implements the core ETL stages that move financial transaction data from generation through PII scrubbing, database ingestion, and audit logging. The distinguishing element is agent instrumentation at every stage boundary — each stage emits structured events and metrics that the agent layer can observe, making the pipeline’s internal behaviour visible and actionable.
⏮️ Previous: Synthetic Data Engineering: Teaching Your Platform What Real Data Looks Like → | ⏭️ Next: Governing with Intelligence: OPA Policies and Agent-Driven Compliance →
Part 1 : From Scripts to Sentience: Building an Agentic Data Platform
Part 2 : Engineering the Foundation: A Production-Grade Development Environment
Part 3 : Designing for Intelligence: The Agentic Data Pipeline Architecture
📖 In This Article
- The Stage Implementation Contract
- Stage 1: Transaction Generation
- Stage 2: PII Scrubbing
- Stage 3: Database Schema Initialisation
- Stage 4: Data Ingestion
- Stage 5: Audit Logging
- Stage 6: Raw File Ingestion
- Agent Observation Hooks
- Prometheus Metrics
- Fail-Fast Error Handling
- Testing Core Stages
- Key Takeaways
📋 The Stage Implementation Contract
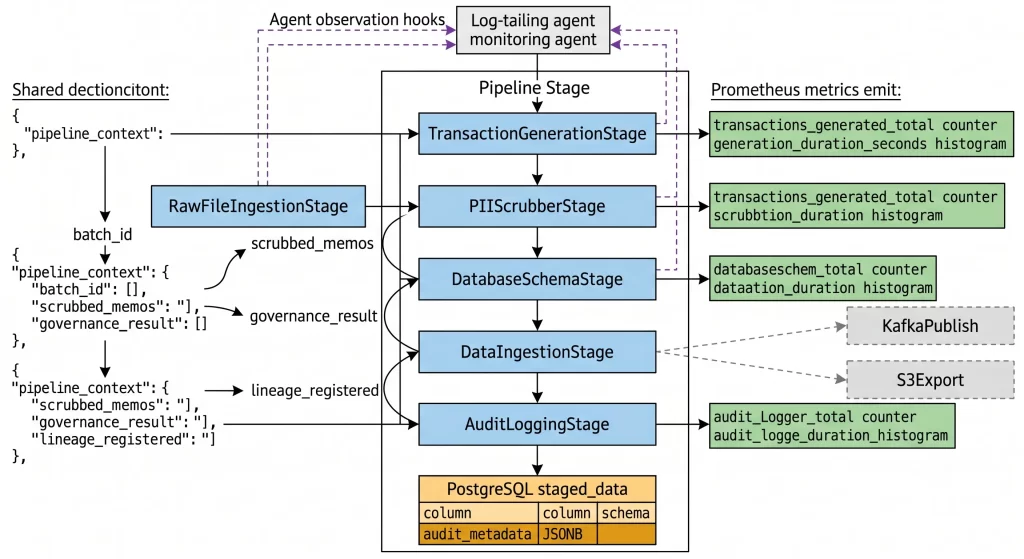
The PipelineStage abstract base class was introduced in Part 3. The core point bears restating here because this article implements it repeatedly: the two-method interface (execute and name) is why every stage in this article can be tested in isolation, composed in any order, and swapped out without touching any other stage. Simplicity at the abstraction level pays dividends at the implementation level.
The pipeline_context dictionary carries metadata between stages — batch IDs, database configuration, agent decisions, governance results — without requiring stages to know about each other’s internal structure.
↑ Back to top · Next: Stage 1: Transaction Generation →
⚙️ Stage 1: Transaction Generation
The TransactionGenerationStage wraps the GenerationAgent from Part 4 and makes synthetic data production a first-class pipeline stage:
class TransactionGenerationStage(PipelineStage):
def execute(self, data, pipeline_context):
batch_size, _ = data
transactions = self.generator.generate_batch(batch_size)
pipeline_context["transactions"] = transactions
return transactions, [""] * len(transactions) # empty memo slots for PIIScrubberThe stage returns a (transactions, memos) tuple that propagates through every subsequent stage. Passing batch_size as input rather than hardcoding it inside the stage means the same implementation works in developer testing (batch_size=10) and production (configurable BATCH_SIZE environment variable).
↑ Back to top · Next: Stage 2: PII Scrubbing →
🔏 Stage 2: PII Scrubbing
Financial transaction memos contain personal information. Under GDPR Article 5(1)(c) — the data minimisation principle — personal data must not be processed beyond the minimum extent necessary for the stated purpose. The PIIScrubberStage enforces this by detecting and redacting PII from memo text before it reaches persistent storage:
class PIIScrubberStage(PipelineStage):
def execute(self, data, pipeline_context):
transactions, _ = data
scrubbed_memos = [self.scrubber.scrub_memo(tx.memo) for tx in transactions]
pipeline_context["scrubbed_memos"] = scrubbed_memos
pipeline_context["pii_scrubbed"] = True
return transactions, scrubbed_memosThe PIIScrubberAgent uses Microsoft Presidio under the hood — an open-source library that combines named entity recognition (NER) with regex patterns to detect PII entity types. Detected entities (PERSON, IBAN_CODE, ID) are replaced with type labels: [PERSON], [IBAN_CODE], [ID]. The scrubbed version goes to analytics; the original is retained in a restricted column for regulatory audit access.
❓ Why the Original Memo Is Preserved
A natural question: if we are removing PII, why keep the original at all?
MiFID II (the EU Markets in Financial Instruments Directive) transaction reporting requirements mandate that original transaction details be available for regulatory inspection for a minimum of five years. GDPR’s right of access (Article 15) requires that data subjects can retrieve the personal data held about them. These obligations pull in opposite directions. The solution is controlled access: original_memo is restricted to compliance and audit roles; scrubbed_memo is what analytics and reporting see. The OPA policy in Part 6 enforces this distinction at the database layer.
↑ Back to top · Next: Stage 3: Database Schema Initialisation →
🗄️ Stage 3: Database Schema Initialisation
The DatabaseSchemaStage ensures the target table exists before ingestion attempts to write to it:
class DatabaseSchemaStage(PipelineStage):
def execute(self, data, pipeline_context):
db_config = load_db_config()
pipeline_context["db_config"] = db_config
schema_sql = Path(SCHEMA_FILE).read_text() # CREATE TABLE IF NOT EXISTS ...
with PooledConnection() as conn:
conn.cursor().execute(schema_sql)
conn.commit()
return dataThe schema SQL uses CREATE TABLE IF NOT EXISTS, making this stage idempotent — running it on a database where the table already exists is a no-op. This matters because the pipeline may restart after a failure; the schema stage must not raise an error just because it has already run. The PooledConnection context manager handles connection pooling transparently — the pool size is configured via environment variable, allowing a single connection in development and a larger pool in production without code changes.
↑ Back to top · Next: Stage 4: Data Ingestion →
💾 Stage 4: Data Ingestion
The DataIngestionStage writes the processed transactions to the staged_data table using batch inserts:
class DataIngestionStage(PipelineStage):
def execute(self, data, pipeline_context):
transactions, scrubbed_memos = data
db_config = pipeline_context.get("db_config") or load_db_config()
batch_rows = build_db_batch_data(transactions, scrubbed_memos, pipeline_context)
with PooledConnection() as conn:
execute_batch(conn.cursor(), INSERT_QUERY, batch_rows)
conn.commit()
return dataexecute_batch() from psycopg2.extras sends all rows in a single round-trip rather than one INSERT per row — roughly 50× faster for a 50-record batch, and the gap widens with batch size. Critically, this function uses parameterised bindings: user data is never interpolated directly into the SQL string. A transaction memo containing '; DROP TABLE staged_data; -- is stored as a literal string, not executed. This is the OWASP A03 (Injection) control at the database layer.
🗂️ The audit_metadata Column
Each row carries an audit_metadata JSONB column that embeds the compliance context directly in the record:
{
"batch_id": "batch-2024-01-15-001",
"governance_decision": "allowed",
"pii_detected": true,
"retention_days": 2555,
"pipeline_version": "1.0.0"
}This is the SOX Section 404 audit trail. Rather than maintaining a separate audit log that must be correlated with the data, the provenance travels with every row. An auditor querying WHERE audit_metadata->>'governance_decision' = 'allowed' immediately sees which records passed governance — no joins, no separate log files. The retention_days value of 2555 corresponds to the seven-year minimum retention period required by SOX Section 802.
↑ Back to top · Next: Stage 5: Audit Logging →
📝 Stage 5: Audit Logging
The AuditLoggingStage writes a batch-level entry to an append-only audit log file:
class AuditLoggingStage(PipelineStage):
def execute(self, data, pipeline_context):
transactions, _ = data
entry = {
"timestamp": datetime.now().isoformat(),
"batch_id": pipeline_context.get("batch_id"),
"operation": "data_ingestion",
"record_count": len(transactions),
"user": "pipeline_agent",
}
with open(self.audit_log_file, "a", encoding="utf-8") as f:
f.write(json.dumps(entry) + "\n")
return dataThe file is opened in append mode ("a") — entries are never overwritten or deleted. In production, this file is shipped to a log aggregation service (Elasticsearch, CloudWatch, or equivalent) that enforces immutability at the storage layer. The user field is always "pipeline_agent" for automated runs, making it easy to distinguish automated pipeline entries from manual administrative actions in the audit trail.
↑ Back to top · Next: Stage 6: Raw File Ingestion →
📂 Stage 6: Raw File Ingestion
Not all financial data arrives as structured transactions. The RawFileIngestionStage handles unstructured inputs — PDF exports, CSV bank statements, JSON feeds:
class RawFileIngestionStage(PipelineStage):
def execute(self, data, pipeline_context):
raw_files = pipeline_context.get("raw_files") or self._scan_raw_input_path()
if not raw_files:
return data
for file_entry in raw_files:
if file_entry.suffix not in self.allowed_extensions:
logger.warning("Rejected file with disallowed extension: %s", file_entry)
continue
record = self._process_and_archive(file_entry)
pipeline_context.setdefault("raw_documents", []).append(record)
return dataThe extension allowlist (pdf, txt, csv, xlsx, json) is an OWASP A01 (Broken Access Control) defence — files with disallowed extensions are explicitly rejected and logged, not silently skipped. Processed files are moved to a dated archive directory; the archive is governed by the same RetentionStage that manages structured transaction data.
↑ Back to top · Next: Agent Observation Hooks →
👁️ Agent Observation Hooks
Every stage emits a structured log entry on completion that agent monitors can consume:
logger.info("Stage completed", extra={
"stage": self.name(),
"batch_id": pipeline_context.get("batch_id"),
"record_count": record_count,
"duration_ms": duration,
})A log-tailing monitoring agent watches these entries and maintains running statistics — average batch size, average stage duration, error rate per stage. When a metric drifts outside expected bounds, the agent can trigger an alert before the pipeline fails. In production, structured log shipping to Elasticsearch plus Kibana dashboards makes this observation available to operations teams without requiring terminal access.
↑ Back to top · Next: Prometheus Metrics →
📊 Prometheus Metrics
The pipeline runner records Prometheus counters and histograms automatically for every stage:
# Success/failure counts per stage
pipeline_stage_executions_total{stage="DataIngestion", status="success"}
# Latency distribution
pipeline_stage_duration_seconds{stage="PIIScrubber", le="0.5"}
# Records processed per batch
pipeline_batch_size{batch_id="batch-2024-01-15-001"}These feed the Grafana dashboards in Part 9 and the alerting rules in Part 16. The /metrics HTTP endpoint on the pipeline service is what Prometheus scrapes every 15 seconds.
↑ Back to top · Next: Fail-Fast Error Handling →
🛑 Fail-Fast Error Handling
Data integrity stages use fail-fast semantics. The pipeline runner is where exceptions are caught — stages just raise:
class PipelineRunner:
def run(self, stages, initial_data, pipeline_context):
data = initial_data
for stage in stages:
try:
data = stage.execute(data, pipeline_context)
except Exception as error:
logger.error("Stage failed: stage=%s error=%s", stage.name(), error)
self.metrics.increment_failures(stage.name())
raise # halt the entire pipeline
return dataA pipeline that continues after the PII scrubber fails would ingest PII-containing data — a GDPR violation. Fail-fast prevents that. Optional stages (Kafka publish, S3 export) are handled differently: their exceptions are caught and logged, and the pipeline continues. The distinction between mandatory and optional is configuration-driven.
↑ Back to top · Next: Testing Core Stages →
🧪 Testing Core Stages
Stages are tested with direct execute() calls — no mocking framework needed. For the ingestion stage, the test runs against a real database instance:
def test_pii_scrubber_redacts_names():
stage = PIIScrubberStage()
tx = Transaction(..., memo="Salary to John Smith ID 1234567890")
_, scrubbed = stage.execute(([tx], [""]), {})
assert "[PERSON]" in scrubbed[0]
assert "John Smith" not in scrubbed[0]def test_ingestion_writes_audit_metadata(test_db):
stage = DataIngestionStage()
context = {"db_config": test_db_config(), "batch_id": "test-001"}
stage.execute(([build_test_transaction()], ["scrubbed"]), context)
row = test_db.execute(
"SELECT audit_metadata FROM staged_data WHERE audit_metadata->>'batch_id' = 'test-001'"
).fetchone()
assert row[0]["batch_id"] == "test-001"The ingestion test runs against a real PostgreSQL instance (started by a pytest-docker fixture) because mocking the database would validate the mock, not the SQL. Part 10 covers the full testing strategy in depth.
🙏 Thank You, Reader
Thank you for working through the stage implementations. The six stages here — generation, scrubbing, schema, ingestion, audit logging, and raw file handling — are the engine that drives every subsequent article. Understanding what each stage does, and why the interfaces are designed the way they are, is the foundation for everything that follows.
📫 Connect With Me
- 💼 LinkedIn: Connect with me on LinkedIn
- 💻 GitHub
↑ Back to top · Next: Key Takeaways →
🔑 Key Takeaways
- The
PipelineStageinterface enables independent testability: callexecute()with known inputs, assert on the output — no mocking framework required. - PII scrubbing must happen before database ingestion; the stage sequence enforces this at the architecture level, making GDPR data minimisation a structural guarantee rather than a process obligation.
- The
audit_metadataJSONB column embeds the SOX compliance trail in the row itself, making compliance queries straightforward — no joins, no separate audit tables. - Parameterised SQL (
execute_batch) is the OWASP injection defence at the data layer — user data never appears directly in SQL strings. - Fail-fast error handling for integrity stages prevents GDPR violations from partially-failed pipeline runs; optional stages use fail-soft semantics controlled by configuration.
Enjoyed this article?
Get notified when the next one is published.
We send one email per new article — no spam, unsubscribe any time.
⚠️ Disclaimer: The information provided on LearnWithNeeraj.com regarding Astrology, Numerology, and other topics is for educational and guidance purposes only.
Not Professional Advice: This content should not be used as a substitute for professional medical, legal, or financial advice. Always consult a certified professional for specific concerns.
Guest Authors: This site features articles by various contributors. The views and interpretations expressed are those of the individual authors and do not necessarily reflect the views of the website administrator.
Your destiny is in your hands. Use this information as a map, not a mandate.