📌 TL;DR
Testing agentic systems requires a fundamentally different approach from testing traditional software. The LLM backbone of an agent is probabilistic — the same input can produce different outputs. The system is distributed — test failures may originate in OPA, Kafka, or the LangGraph state machine, not in the code under test. This article covers the full testing strategy: unit tests for deterministic components, integration tests against real services, property-based testing for transformation logic, and adversarial tests designed to break agents deliberately.
⏮️ Previous: Part 9 — Production-Grade Deployment: Kubernetes, Terraform, and Autonomous Scaling → | ⏭️ Next: Part 11 — Zero-Trust Data Governance: Security Architecture for Agentic Platforms →
📖 Series context: In Part 9 — Kubernetes Deployment, we shipped the platform to production with Terraform-provisioned EKS, rolling updates, Kafka-lag HPA, and zero-downtime deployments. Now we address the hardest quality assurance question in agentic engineering: how do you test a system whose outputs are probabilistic and whose failure modes emerge from agent coordination rather than individual components? In Part 11 — Zero-Trust Security, we harden the deployed system with authentication, OPA-enforced access control, and OWASP/ISO 27001 controls.
💡 Quick stats: 🔬 4 test layers — unit, integration, property-based, chaos · 🎲 Hypothesis found a PII regex bug that no hand-crafted test caught · 🏥 95% recall minimum — PII detection threshold enforced in CI · 💥 3 failure modes tested: fail-closed (OPA), fail-soft (Kafka), fail-fast (database)
🧩 The Testing Challenge for Agentic Systems
If you are building or operating an agentic platform and struggling to write tests that don’t flake — this section names exactly why traditional testing breaks for probabilistic, distributed systems. By the end you will have a four-layer testing strategy: deterministic unit tests for pipeline stages, real-service integration tests that catch SQL and serialisation bugs mocks cannot, property-based tests that find edge cases automatically, and chaos tests that verify designed failure modes actually work.
Probabilistic outputs: An LLM-backed agent asked to classify a transaction memo will not always return the same classification. The output depends on the model, the temperature parameter, the context window contents, and non-deterministic sampling. Writing a test that asserts result == "salary_transaction" will be flaky.
Emergent behaviour: Individual agents may behave correctly in isolation but produce unexpected results when they interact. The compliance audit agent may correctly evaluate a single transaction, but when three agents are coordinating — validation, compliance, and lineage — the interaction may surface edge cases that no individual agent test would catch.
The response to these challenges is not to avoid testing — it is to test differently. Unit tests cover deterministic logic. Integration tests cover service interactions. Property-based tests cover invariants that must hold regardless of input. Adversarial tests probe agent behaviour under hostile conditions. Together, these form a testing strategy that provides meaningful coverage for a system where traditional assertion-based testing is insufficient.
↑ Back to top · Next: Unit Testing: Isolating Deterministic Logic →
🔬 Unit Testing: Isolating Deterministic Logic
Pipeline stages are deterministic: the same input produces the same output. These are the easiest and most valuable tests in the suite.
def test_transaction_generation_stage_produces_correct_batch_size():
stage = TransactionGenerationStage()
transactions, memos = stage.execute((20, 0), {})
assert len(transactions) == 20
assert len(memos) == 20
def test_pii_scrubber_stage_removes_names():
stage = PIIScrubberStage()
tx = Transaction(
transaction_date=date.today(),
amount=5000.0,
currency="USD",
transaction_type="salary",
from_account="BANK_SALARY",
to_account="US12345678901234567890",
memo="Salary to Jane Doe ID 1234567890",
)
_, scrubbed = stage.execute(([tx], [""]), {})
assert "Jane Doe" not in scrubbed[0]
assert "[PERSON]" in scrubbed[0]
def test_audit_logging_stage_writes_entry(tmp_path):
log_file = tmp_path / "audit.log"
stage = AuditLoggingStage(config={"audit_log_file": str(log_file)})
transactions = [build_test_transaction() for _ in range(5)]
stage.execute((transactions, [""]*5), {"batch_id": "test-001"})
entries = [json.loads(line) for line in log_file.read_text().splitlines()]
assert len(entries) == 1
assert entries[0]["batch_id"] == "test-001"
assert entries[0]["record_count"] == 5These tests use no mocks. The PIIScrubberStage test exercises the actual Presidio NER pipeline. The AuditLoggingStage test writes to a real file in a tmp_path fixture. Mocking would make these tests faster but would not actually test whether Presidio is detecting PII or whether the JSON serialisation is correct.
↑ Back to top · Next: Integration Testing: Real Services, Real Failures →
🔗 Integration Testing: Real Services, Real Failures
The most valuable integration tests run against real service instances, not mocks. Mocking the database connection for the DataIngestionStage test would validate that the code calls the mock correctly — it would not validate that the SQL query is valid, that the column types match, or that the batch insert handles duplicate keys gracefully.
@pytest.fixture(scope="session")
def real_database(docker_services):
"""Fixture that starts and waits for a test PostgreSQL instance."""
docker_services.wait_until_responsive(
timeout=30.0,
pause=0.1,
check=lambda: is_database_available(),
)
yield
# Teardown: test database is dropped after session
def test_data_ingestion_writes_correct_audit_metadata(real_database):
stage = DataIngestionStage()
transactions = [build_test_transaction() for _ in range(3)]
context = {
"batch_id": "integration-test-001",
"db_config": test_db_config(),
"contains_pii": True,
}
stage.execute((transactions, ["scrubbed"]*3), context)
with test_db_connection() as conn:
rows = conn.execute(
"""
SELECT audit_metadata
FROM staged_data
WHERE audit_metadata->>'batch_id' = 'integration-test-001'
"""
).fetchall()
assert len(rows) == 3
for row in rows:
meta = row[0]
assert meta["batch_id"] == "integration-test-001"
assert meta["contains_pii"] is TrueThe docker_services fixture from pytest-docker starts the PostgreSQL container for the test session and tears it down afterward. This gives each test session a clean, isolated database.
⚖️ Testing OPA Policy Evaluation
OPA integration tests verify that the Rego policies are evaluated correctly against the pipeline’s actual request format:
@pytest.fixture(scope="session")
def opa_server(docker_services):
docker_services.wait_until_responsive(
timeout=30.0, pause=0.5,
check=lambda: requests.get("http://localhost:8181/health").ok,
)
def test_opa_allows_valid_pipeline_write(opa_server):
client = OPAPolicyClient("http://localhost:8181")
policy_input = {
"identity": "pipeline",
"action": "write",
"resource": {"type": "dataset", "name": "staged_data"},
"context": {
"audit_logged": True,
"retention_days": 2555,
"contains_pii": False,
},
}
assert client.evaluate("agentic/allow", policy_input) is True
def test_opa_denies_write_with_unlogged_pii(opa_server):
client = OPAPolicyClient("http://localhost:8181")
policy_input = {
"identity": "pipeline",
"action": "write",
"resource": {"type": "dataset", "name": "staged_data"},
"context": {
"audit_logged": True,
"retention_days": 2555,
"contains_pii": True,
"pii_scrubbed": False, # PII detected but not yet scrubbed
},
}
assert client.evaluate("agentic/allow", policy_input) is FalseThese tests are the specification for the Rego policies — they document what the policies must allow and deny, and they catch regressions immediately when policies are modified.
↑ Back to top · Next: Property-Based Testing →
🎲 Property-Based Testing
Property-based testing is particularly valuable for data transformation logic. Instead of testing specific inputs, it tests invariants — properties that must hold for all valid inputs.
The Hypothesis library generates random valid inputs and finds edge cases that human-written tests miss:
from hypothesis import given, settings
from hypothesis import strategies as st
@given(
amount=st.floats(min_value=0.01, max_value=1_000_000, allow_nan=False, allow_infinity=False),
currency=st.sampled_from(["USD", "EUR", "GBP", "SGD"]),
transaction_type=st.sampled_from(TRANSACTION_TYPES),
)
def test_pii_scrubber_never_corrupts_amount(amount, currency, transaction_type):
"""The PII scrubber must not modify the transaction amount field."""
stage = PIIScrubberStage()
tx = Transaction(
transaction_date=date.today(),
amount=amount,
currency=currency,
transaction_type=transaction_type,
from_account="TEST",
to_account="TEST",
memo=f"Payment of {currency} {amount:.2f}",
)
returned_transactions, _ = stage.execute(([tx], [""]), {})
assert returned_transactions[0].amount == amount
@given(
amounts=st.lists(
st.floats(min_value=0.01, max_value=1_000_000),
min_size=1, max_size=100,
)
)
def test_audit_log_record_count_matches_batch(tmp_path, amounts):
"""Audit log must record the exact count of processed transactions."""
log_file = tmp_path / "audit.log"
stage = AuditLoggingStage(config={"audit_log_file": str(log_file)})
transactions = [
Transaction(
transaction_date=date.today(),
amount=a, currency="USD",
transaction_type="payment",
from_account=None, to_account=None, memo="test",
)
for a in amounts
]
stage.execute((transactions, [""]*len(transactions)), {"batch_id": "prop-test"})
entry = json.loads(log_file.read_text().splitlines()[0])
assert entry["record_count"] == len(amounts)Hypothesis found a subtle bug in an early version of the PII scrubber: when the memo contained an amount formatted as 1,000.50 (with a thousands separator), the scrubber’s regex for ID detection was matching the five-digit sequence 1,000 as a national ID number. The property-based test caught this through random generation long before a human tester would have constructed that specific input.
💡 Pro tip: Property-based testing is not a replacement for unit tests — it is a bug-finding amplifier. Write the unit test first to document the intended behaviour, then add a Hypothesis test to find the inputs your unit test never thought to try. The combination catches bugs at two completely different levels of specificity.
↑ Back to top · Next: Testing Agent Behaviour →
🤖 Testing Agent Behaviour
Agent behaviour tests accept that LLM outputs are probabilistic and test structural properties instead of exact values:
def test_governance_advisor_recommendation_is_human_reviewable():
"""Any policy change recommended by the agent must be flagged for human review."""
advisor = AgentGovernanceAdvisor(
llm_client=MockLLMClient(),
policy_analyzer=PolicyAnalyzer(),
)
violations = [
PolicyViolation(policy_rule="valid_currency", count=50),
PolicyViolation(policy_rule="valid_currency", count=50),
]
recommendation = advisor.analyze_violation_trends(violations)
assert recommendation.requires_human_review is True
def test_pii_scrubber_agent_consistency():
"""The scrubber must return consistent entity labels for the same entity type."""
scrubber = PIIScrubberAgent()
memo_1 = "Payment to Alice Johnson ID 1234567890"
memo_2 = "Transfer from Bob Smith ID 9876543210"
result_1 = scrubber.scrub_memo(memo_1)
result_2 = scrubber.scrub_memo(memo_2)
# Both should use the same label format, not random substitutions
assert "[PERSON]" in result_1
assert "[PERSON]" in result_2
assert result_1.count("[PERSON]") == 1
assert result_2.count("[PERSON]") == 1NIST AI RMF‘s MEASURE function requires that AI systems’ performance be quantified and tracked. For the PII scrubber, the metrics to track are: precision (what proportion of identified entities are actual PII?), recall (what proportion of actual PII is identified?), and false negative rate (PII that was not detected).
A CI job runs the PII scrubber against a labeled test dataset and fails if recall drops below 95%. This keeps the compliance component’s performance above the threshold required for GDPR compliance.
↑ Back to top · Next: Chaos Engineering →
💥 Chaos Engineering
Chaos engineering tests system resilience under failure conditions. For the agentic platform, the key failure scenarios are:
OPA unavailability: The pipeline should halt (fail-closed), not continue without governance evaluation.
def test_pipeline_halts_when_opa_unavailable(monkeypatch):
def mock_opa_evaluate(*args, **kwargs):
raise ConnectionError("OPA service unavailable")
monkeypatch.setattr(OPAPolicyClient, "evaluate", mock_opa_evaluate)
stage = OPAPolicyEnforcementStage(config={"fail_on_policy_error": True})
with pytest.raises(RuntimeError, match="Policy enforcement unavailable"):
stage.execute(test_data(), {})Kafka unavailability: The Kafka publish stage is optional and should degrade gracefully.
def test_kafka_failure_is_non_blocking(monkeypatch):
def mock_kafka_produce(*args, **kwargs):
raise Exception("Kafka broker unavailable")
monkeypatch.setattr("kafka.KafkaProducer", mock_kafka_produce)
stage = KafkaPublishStage()
# Should not raise — Kafka publish is optional
result = stage.execute(test_data(), {})
assert result == test_data() # Data passed through unchangedDatabase unavailability: The data ingestion stage should fail loudly — data loss is not acceptable.
def test_ingestion_fails_when_db_unavailable(monkeypatch):
monkeypatch.setattr(
"libs.common.database.PooledConnection.__enter__",
lambda self: (_ for _ in ()).throw(Exception("DB connection failed"))
)
stage = DataIngestionStage()
with pytest.raises(Exception):
stage.execute(test_data(), {"db_config": {}})These tests verify that the failure modes designed into each stage (fail-closed for governance, fail-soft for optional services, fail-fast for required services) actually work as intended.
↑ Back to top · Next: CI/CD Test Pipeline →
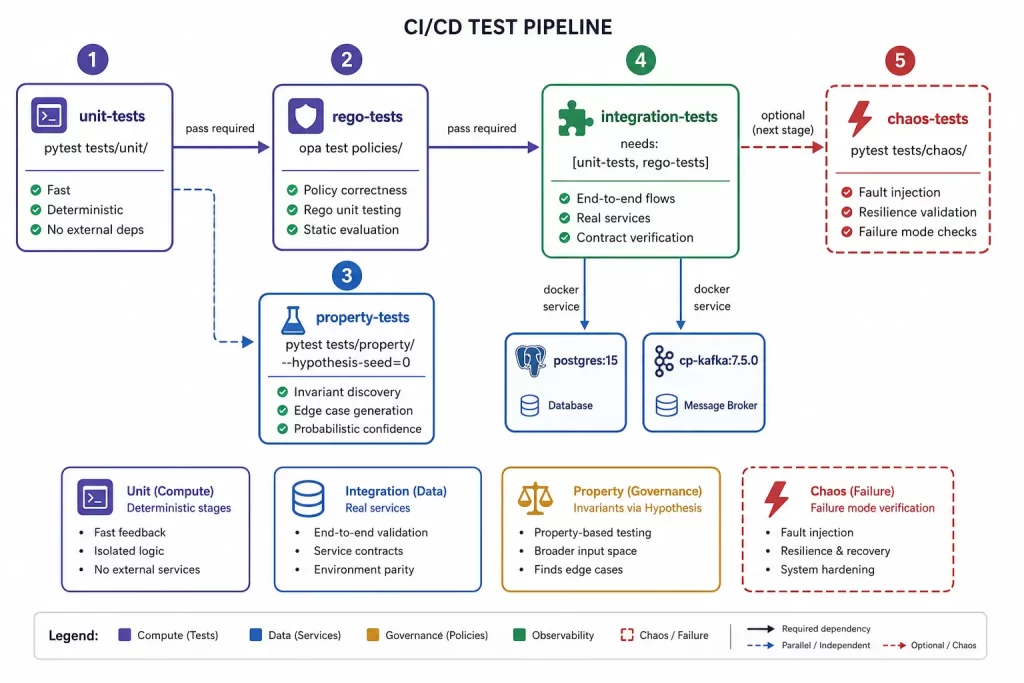
🚀 CI/CD Test Pipeline
The test pipeline runs in sequence, with each stage only running if the previous stages pass:
# .github/workflows/tests.yml
jobs:
unit-tests:
runs-on: ubuntu-latest
steps:
- run: pytest tests/unit/ -v --tb=short
rego-tests:
runs-on: ubuntu-latest
steps:
- run: opa test policies/ -v
integration-tests:
needs: [unit-tests, rego-tests]
services:
postgres:
image: postgres:15
env:
POSTGRES_PASSWORD: testpassword
kafka:
image: confluentinc/cp-kafka:7.5.0
steps:
- run: pytest tests/integration/ -v --tb=short
property-tests:
needs: [unit-tests]
steps:
- run: pytest tests/property/ -v --hypothesis-seed=0The --hypothesis-seed=0 flag makes property-based tests deterministic in CI while still exploring the input space. When Hypothesis finds a failing case in CI, the seed allows exact reproduction locally.
↑ Back to top · Next: Key Takeaways →
❓ Frequently Asked Questions
Common questions about testing agentic AI systems, answered from real-world implementation experience building a regulated financial data platform.
How do you test an AI agent that produces non-deterministic outputs?
Test structural invariants rather than exact output values. Instead of asserting result == "salary_transaction" (which will be flaky), assert properties that must hold regardless of the specific output: recommendation.requires_human_review is True, "[PERSON]" in scrubbed_memo, len(result) > 0. For quantitative performance requirements like PII detection recall, run against a labeled test dataset in CI and fail the build if recall drops below 95%. This satisfies the NIST AI RMF MEASURE function without brittle exact-match assertions.
What is property-based testing and when should you use it for data pipelines?
Property-based testing generates random valid inputs and verifies that invariants hold across all of them. The Hypothesis library is the Python standard — you define strategies (e.g., st.floats(min_value=0.01, max_value=1_000_000)) and Hypothesis generates hundreds of test cases automatically. Use it for data transformation logic where you have clear invariants: the PII scrubber must never modify the amount field, the audit log record_count must equal the batch size. It found a PII regex bug that matched thousands-separators as ID numbers — no hand-crafted test would have found it.
What is chaos engineering for data pipelines and how do you implement it?
Chaos engineering verifies that designed failure modes actually work as intended. For a data pipeline, inject failures using pytest’s monkeypatch: mock OPA to raise ConnectionError and verify the pipeline raises RuntimeError (fail-closed). Mock Kafka to raise an exception and verify data passes through unchanged (fail-soft). Mock the database and verify an exception is raised immediately (fail-fast). These tests are not about random failure — they are about verifying that each component’s explicit failure policy is correctly implemented and has not been accidentally broken.
How do you test OPA Rego policies in CI/CD?
Two complementary approaches. First, use opa test policies/ -v directly — OPA has a built-in test framework where Rego test files (prefixed test_) assert specific policy decisions. Second, run Python integration tests against a real OPA container started by pytest-docker: call OPAPolicyClient.evaluate() with the exact request format the pipeline uses, and assert the allow/deny decision. The Python integration tests serve as the specification for the Rego policies — they document what must be allowed and denied, and fail immediately if a policy change breaks expected behaviour.
↑ Back to top · Next: Key Takeaways →
🔑 Key Takeaways
- Test deterministic pipeline stages with direct
execute()calls and no mocks — mocks validate mock behaviour, not real behaviour; the Presidio NER pipeline and JSONB serialisation must be exercised directly to catch real bugs. - Integration tests must run against real service instances — they catch SQL bugs, connection pool exhaustion, and Kafka serialisation issues that mock-based tests structurally cannot; use
pytest-dockerfor clean, isolated service instances per session. - Property-based testing with Hypothesis finds edge cases human-written tests miss — the thousands-separator PII regex bug was caught by random input generation after thousands of hand-crafted tests never triggered it.
- Agent behaviour tests must assert invariants, not exact LLM outputs — assert
requires_human_review is Trueand"[PERSON]" in result; exact string assertions on LLM output are inherently flaky and will fail in production. - Chaos tests verify that each component’s failure policy is correctly implemented — OPA unavailability must halt the pipeline (fail-closed), Kafka failure must pass data through (fail-soft), database failure must raise immediately (fail-fast); these properties rot silently without tests.
- NIST AI RMF MEASURE function requires CI-enforced performance thresholds — PII detection recall below 95% must fail the build; a compliance control that degrades silently is more dangerous than one that fails loudly.
🙏 Thank You, Reader
Thank you for reading. Testing agentic systems is one of the most intellectually demanding parts of building this platform — the probabilistic nature of LLMs, the distributed failure modes, and the emergent behaviour of coordinating agents all require rethinking assumptions that hold for deterministic software. If this article gave you a framework for approaching those challenges, the next article addresses the security layer: zero-trust governance and how the platform enforces it at every boundary.
📫 Connect With Me
- 💼 LinkedIn: Connect with me on LinkedIn
- 💻 GitHub
Enjoyed this article?
Get notified when the next one is published.
We send one email per new article — no spam, unsubscribe any time.
⚠️ Disclaimer: The information provided on LearnWithNeeraj.com regarding Astrology, Numerology, and other topics is for educational and guidance purposes only.
Not Professional Advice: This content should not be used as a substitute for professional medical, legal, or financial advice. Always consult a certified professional for specific concerns.
Guest Authors: This site features articles by various contributors. The views and interpretations expressed are those of the individual authors and do not necessarily reflect the views of the website administrator.
Your destiny is in your hands. Use this information as a map, not a mandate.