📌 TL;DR
Most data engineering tutorials teach you to move data from A to B. This series teaches you to build a platform where intelligent agents govern that movement — catching compliance violations before they become incidents, detecting data quality drift before it corrupts reports, and coordinating complex multi-step workflows without human intervention. Over 17 parts, I walk through every layer of a production-grade agentic data platform built on Python, LangGraph, OPA, OpenMetadata, Kafka, MinIO, and a Prometheus + Grafana observability stack.
⏭️ Next: Engineering the Foundation: A Production-Grade Development Environment →
🛠️ Why I Built This
Three years ago I was maintaining what looked, from a distance, like a healthy data platform. Batch jobs ran on schedule. Dashboards updated overnight. Stakeholders got their reports. But under the surface, the system was held together by duct tape: manual validation scripts that ran occasionally, compliance checks that existed only in documentation, and data lineage that lived entirely in one senior engineer’s head.
The breaking point came during a regulatory audit. An examiner asked a simple question: “Show me the complete journey of this transaction record from source system to reporting database.” We couldn’t answer it — not completely, not with the level of traceability that Basel III and MiFID II actually require. We scrambled. We survived that audit. But I knew the platform needed a fundamental rethink.
The rethink I landed on wasn’t “better tooling.” It was a different mental model: instead of treating data pipelines as plumbing — passive conduits that move data from place to place — what if the pipeline itself could reason about what it was carrying? What if compliance was enforced not by a checklist a human reviews quarterly, but by a policy engine that evaluates every transaction at the moment it enters the system? What if a validation failure didn’t silently corrupt downstream tables, but instead triggered an agent that diagnosed the root cause and proposed a fix?
That mental model is agentic data engineering, and this series is a 17-part walk through how to build a platform that embodies it.
↑ Back to top · Next: What “Agentic” Actually Means →
🧠 What “Agentic” Actually Means
The word “agent” gets overloaded. In this series, an AI agent is a software component that combines three capabilities that traditional pipeline stages lack:
- 👁️ Observation: An agent can inspect the data flowing through the pipeline and its own operational context — not just “does this row have a null value?” but “has the proportion of null values in this column increased by more than 15% compared to last week?”
- ⚙️ Reasoning: An agent can apply policies, heuristics, or LLM-backed inference to interpret what it observes. The policy might be an OPA Rego rule that checks a transaction against GDPR data minimisation requirements. The heuristic might be a statistical model that detects anomalous payment patterns. The LLM inference might classify an ambiguous memo field against a compliance taxonomy.
- ⚡ Action: An agent can respond to what it observes and reasons about — rejecting a record, triggering an alert, updating metadata in OpenMetadata, publishing an event to Kafka, or escalating to a human reviewer when the decision exceeds its confidence threshold.
The platform in this series is built around a pipeline where agents are first-class citizens, not afterthoughts. Every pipeline stage emits structured events that agents can consume. Every agent action is logged to an immutable audit trail. Every policy decision can be traced back to the rule that triggered it.
This is not a traditional ETL pipeline with a chatbot bolted on. The intelligence is structural.
↑ Back to top · Next: The Problem This Platform Solves →
🎯 The Problem This Platform Solves
To make this concrete, consider the operational reality of a financial services firm processing transaction data at scale:
- Volume and velocity: Thousands of transactions per hour, each requiring validation against business rules, regulatory policies, and data quality standards. Manual review is not viable.
- Regulatory complexity: A single transaction may be subject to GDPR (data subject rights, consent tracking), SOX (audit trail requirements, segregation of duties), Basel III/IV (capital adequacy reporting accuracy), MiFID II (transaction reporting, best execution), and FATF/AML-KYC (suspicious activity detection). These frameworks overlap, sometimes conflict, and evolve. A static compliance checklist becomes outdated the moment it’s written.
- Data quality at the source boundary: External data feeds are unreliable. Currencies can appear in unexpected formats. Amounts can be negative when they shouldn’t be. Timestamps can arrive out of order. A naive pipeline that passes malformed data to downstream analytics systems creates compounding problems that are expensive to debug.
- Operational visibility: When something goes wrong at 2 AM, the on-call engineer needs to know what failed, why it failed, and what data was affected — without reading through logs manually.
The agentic platform addresses each of these:
- ✅ OPA-backed policy enforcement at ingestion time, with every decision logged
- ✅ A
ValidationAgentthat inspects data quality across configurable rule sets - ✅ A
PIIScrubberAgentthat detects and redacts personal identifiers before storage - ✅ A
LineageRegistryStagethat captures OpenLineage-compatible provenance metadata - ✅ A LangGraph orchestrator that coordinates agents through complex multi-step workflows
- ✅ A Prometheus + Grafana observability stack that surfaces pipeline health in real time
↑ Back to top · Next: The Technology Stack →
🏗️ The Technology Stack
The stack is deliberately chosen for enterprise operability — each component is a de facto standard in its domain, with strong community support and production track records.
💻 Core Runtime
🐍 Python 3.11+
Lingua franca of data engineering and ML tooling. Rich ecosystem, async support, and type annotations make it the natural choice for both pipeline logic and agent orchestration.
✅ Pydantic
Data validation and settings management with type safety. Every transaction that enters the pipeline is a Pydantic model — invalid data is caught at the boundary before it can propagate.
🔀 LangGraph
Stateful multi-agent workflow orchestration. Models agent workflows as directed graphs — nodes are agent invocations, edges are control-flow transitions. Makes loops, conditional branching, and human approval gates first-class concepts.
🗄️ Data Infrastructure
📨 Apache Kafka
Distributed event streaming. Durable, ordered, replayable streams — failed pipeline runs re-consume from the last committed offset. Also the agent-to-agent message bus.
🪣 MinIO
S3-compatible object storage for raw landing and lakehouse layers. Same API as AWS S3 — no cloud account needed during development.
🐘 PostgreSQL
Workhorse relational store for processed transaction data. Also persists LangGraph workflow checkpoints — workflows can pause at approval gates, survive pod restarts, and resume exactly where they left off.
🧊 Apache Iceberg
Open table format for large-scale analytical reads (optional, toggled by env var). Adds schema evolution, time travel, and partition pruning on top of object storage.
⚖️ Governance & Compliance
🛡️ Open Policy Agent
Evaluates declarative Rego policies against any JSON input. Every pipeline write is evaluated before data reaches the database. OPA turns compliance from a checklist into a runtime guard.
🗂️ OpenMetadata
Open-source metadata platform for data cataloging, lineage visualization, and quality tracking. System of record for what datasets exist, who owns them, and where they came from.
🔍 Presidio
Microsoft’s open-source PII detection and anonymisation library. Uses NLP named entity recognition to identify personal identifiers in free-text fields and replace them with labelled placeholders like [PERSON] or [ID].
🤖 AI / LLM Layer
⚡ LLM Provider Abstraction
Thin wrapper to switch between local Ollama and cloud inference with a single env var change (LLM_PROVIDER=local|cloud). Same agent code runs on a laptop and in production.
🔎 Qdrant
Vector similarity search for RAG-backed agent memory. Agents query historical context — “has a transaction with these characteristics been flagged before?” — without full table scans.
🧪 Garak
Open-source LLM vulnerability scanner. Systematically probes agents for jailbreaks, prompt injection, data exfiltration, and role abuse. Runs in CI on every model update.
📊 Observability
📈 Prometheus
Pull-based metrics collection. Every pipeline stage and agent invocation increments counters and populates histograms scraped on a regular interval.
📉 Grafana
Dashboard and alerting layer over Prometheus. The dashboards are not monitoring overlays — they are the primary operational interface.
📋 Structured Logging
Every agent action, policy decision, and pipeline execution logged as machine-parseable JSON. Log aggregation and alerting tractable without custom parsers.
🐳 Development Environment
🐳 Docker Compose
A full local stack with over ten services mirroring the production topology. Run the entire platform — Kafka, PostgreSQL, OPA, OpenMetadata, MinIO, Prometheus, Grafana, Ollama — on a laptop with a single docker compose up.
This stack maps to the TOGAF Technology Architecture layer — a framework from The Open Group that structures enterprise architecture into four layers: Business, Data, Application, and Technology. Kafka and MinIO form the data tier, PostgreSQL and Iceberg the persistence tier, OPA and OpenMetadata the governance tier, and Prometheus/Grafana the management tier. Using TOGAF as a lens ensures no layer is treated as an afterthought — governance sits at the same level as storage, not above it as an optional add-on.
↑ Back to top · Next: Platform Architecture →
🗺️ Platform Architecture
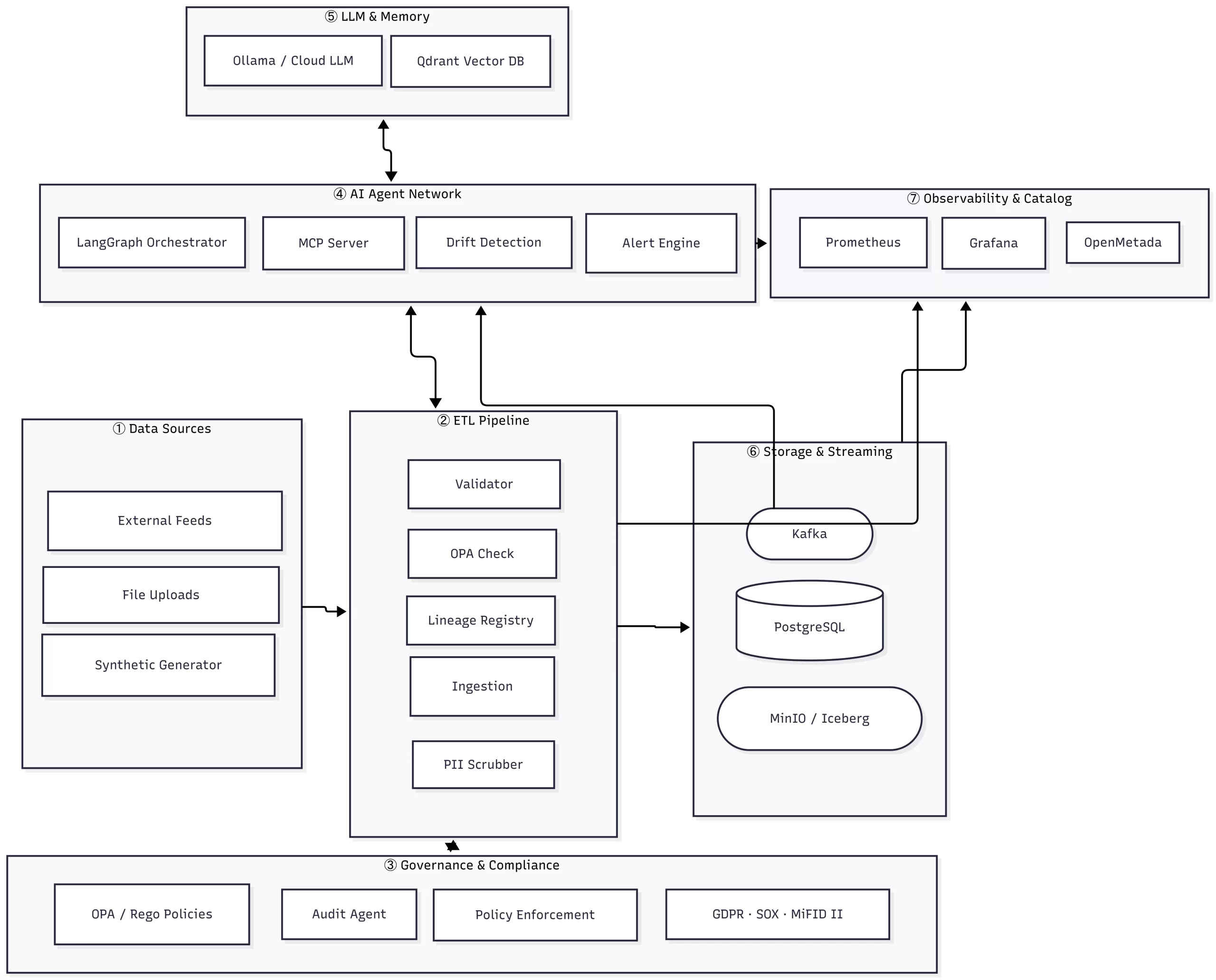
↑ Back to top · Next: The 17-Part Journey →
📋 The 17-Part Journey
| Part | Title | What You Will Learn |
|---|---|---|
| 1 | This article ◀ | Why agentic data engineering, technology overview |
| 2 | Development Environment | Docker Compose stack, 12-Factor configuration |
| 3 | Pipeline Architecture | Stage-based design, agent integration patterns |
| 4 | Synthetic Data Engineering | Generating realistic financial test data |
| 5 | Core ETL Stages | Extraction, PII scrubbing, ingestion, audit logging |
| 6 | Governance & Compliance | OPA policies, OpenMetadata, DAMA DMBOK alignment |
| 7 | Streaming Capabilities | Kafka integration, event-driven agent triggers |
| 8 | Documentation Best Practices | Living docs, ADRs, agent-readable tool descriptions |
| 9 | Deployment & Scaling | Kubernetes, Terraform, autonomous scaling patterns |
| 10 | Testing Strategies | Testing agentic systems, adversarial validation |
| 11 | Data Governance & Security | Zero-trust model, GDPR/SOX implementation |
| 12 | Multi-Agent Orchestration | LangGraph, A2A protocol, LLM provider abstraction |
| 13 | Red Teaming | Adversarial testing of AI agents, NIST AI RMF |
| 14 | MCP Server Architecture | Internal tool registry, secure agent execution |
| 15 | Validation & Lineage Tracking | OpenLineage, audit trails, FAIR Data Principles |
| 16 | Alert & Notification Systems | Proactive intelligence, escalation policies |
| 17 | Lessons & Future Outlook | What I learned, where agentic data engineering goes next |
↑ Back to top · Next: Design Principles →
📐 Design Principles
Several principles guided every architectural decision I made. I will return to these repeatedly throughout the series.
📜 Policy Belongs in Code, Not Documents
Every compliance requirement that lives in a Word document is a compliance requirement that will not be enforced consistently. The OPA Rego policies in this platform are version-controlled, tested, and evaluated at runtime. When the regulatory landscape changes — and it will — you update a .rego file, run the test suite, and deploy. No manual process updates required.
This aligns with how DAMA DMBOK (the Data Management Body of Knowledge) approaches data governance: governance should be operationalised through automated controls, not manual oversight. DAMA defines eleven Knowledge Areas spanning data quality, metadata, security, and lifecycle management; the OPA policies in this platform are a direct implementation of the governance controls DAMA describes in its Policy Management and Data Quality KAs.
🎯 Agents Are Narrow, the Orchestrator Is Broad
A mistake I see often in agentic system design is making agents responsible for too much. Agents in this platform are narrow in scope: each does one thing well. The ValidationAgent validates. The PIIScrubberAgent scrubs PII. The compliance audit agent evaluates policy. Coordination between agents is the orchestrator’s job.
Narrow scope makes individual agents testable, replaceable, and explainable — which matters when a regulator asks why a particular record was flagged.
🔗 Lineage Is Not Optional
FAIR Data Principles — Findable, Accessible, Interoperable, Reusable — are a set of guiding principles widely adopted across data engineering. Data is only useful if people and machines can find it, access it through a standard interface, combine it with other datasets, and reuse it without reverse-engineering how it was produced. None of these properties can be satisfied without lineage. Every pipeline stage in this platform emits OpenLineage-compatible metadata — producing a complete provenance graph that answers an auditor’s “show me the journey of this record” question in seconds.
🔭 Observability Is Architectural, Not Operational
Prometheus metrics are not added to a system after it is built; they are designed in from the start. Every pipeline stage, every agent invocation, every policy decision emits structured metrics. The Grafana dashboards are not monitoring overlays — they are the primary operational interface.
🧩 The LLM Is a Component, Not the Platform
LLMs are powerful but unpredictable. In this platform, LLM-backed reasoning is isolated to specific agent nodes that operate on narrow, well-defined inputs. The LLM cannot modify pipeline configuration, cannot write to the database directly, and cannot bypass OPA policy checks. When the LLM is unavailable — local Ollama server down, cloud API key expired — the pipeline continues using deterministic fallbacks.
This matches the NIST AI RMF GOVERN function, which requires that AI systems be deployed with defined operating boundaries, human oversight mechanisms, and documented fallback procedures — exactly the constraints the LLM isolation pattern enforces.
↑ Back to top · Next: What Makes This Series Different →
✨ What Makes This Series Different
The internet already contains thousands of data engineering tutorials. Here is what distinguishes this series:
- 📚 Every code example comes from a working codebase. The stages, agents, and orchestrators described in each article are implemented in the companion repository. Nothing is pseudocode for illustration purposes.
- ⚡ The agentic layer is structural, not decorative. Some “AI-powered data engineering” articles add a call to an LLM API at the end of a batch job and call it agentic. In this series, agents are integral — they participate in ingestion, governance, validation, and lineage capture.
- ⚖️ Enterprise compliance is treated seriously. GDPR, SOX, Basel III/IV, MiFID II, and FATF/AML-KYC map to specific OPA policies, specific audit log fields, and specific data handling procedures shown in code.
- 🔭 The full operational picture is covered. Production systems need more than application code. Parts 9 through 11 cover deployment, testing, and security in depth.
↑ Back to top · Next: Prerequisites →
✅ Prerequisites
🔧 What You Need to Know
- Comfortable Python development experience (3.10+)
- Familiarity with Docker and Docker Compose
- Basic understanding of data pipelines (extract, transform, load)
- Awareness of, but not deep expertise in, LLMs and AI agents
You do not need prior LangGraph experience. You do not need to know OPA. You do not need a cloud account — the full stack runs locally.
↑ Back to top · Next: Let’s Build →
🚀 Let’s Build
Data engineering is undergoing a genuine paradigm shift. The skills that made someone excellent at building traditional batch pipelines are still valuable, but they are increasingly table stakes. The differentiating skill is understanding how to make a data platform reason about itself — how to embed intelligence into the data infrastructure, not just the applications on top of it.
That is what agentic data engineering offers. Let’s build one together.
🙏 Thank You, Reader
Thank you for beginning this journey. Building an agentic data platform is genuinely hard work — harder than the tooling documentation suggests — and the fact that you are here means you are ready to engage with that complexity seriously. I hope this series saves you from some of the mistakes I made and accelerates your path to a platform that earns your organisation’s trust.
📫 Connect With Me
- 💼 LinkedIn: Connect with me on LinkedIn
- 💻 GitHub: Explore the full codebase
↑ Back to top · Next: Key Takeaways →
🔑 Key Takeaways
- Agentic data engineering means pipelines where AI agents observe, reason about, and act on data — not passive conduits with AI bolted on afterward.
- Financial data platforms face compound compliance obligations (GDPR, SOX, Basel III/IV, MiFID II, FATF) that require policy-as-code approaches, not document-based checklists.
- The platform uses OPA for governance, LangGraph for multi-agent orchestration, OpenMetadata for lineage, and Prometheus + Grafana for observability.
- Agents should be narrow in scope, testable in isolation, and bounded by explicit policy controls aligned with NIST AI RMF.
- Lineage is not a nice-to-have; FAIR Data Principles and regulatory auditability both depend on it.
Enjoyed this article?
Get notified when the next one is published.
We send one email per new article — no spam, unsubscribe any time.
⚠️ Disclaimer: The information provided on LearnWithNeeraj.com regarding Astrology, Numerology, and other topics is for educational and guidance purposes only.
Not Professional Advice: This content should not be used as a substitute for professional medical, legal, or financial advice. Always consult a certified professional for specific concerns.
Guest Authors: This site features articles by various contributors. The views and interpretations expressed are those of the individual authors and do not necessarily reflect the views of the website administrator.
Your destiny is in your hands. Use this information as a map, not a mandate.