📌 TL;DR
Documentation for an agentic platform is not just for humans. Agents need to understand their own capabilities, the tools available to them, and the data schemas they process. This article covers the four-layer documentation as code strategy: Python docstring standards, Architecture Decision Records, YAML data dictionaries, and how OpenMetadata serves as the platform’s living documentation layer. One principle applies throughout: documentation that is not automatically verified tends to go stale — and in a regulated financial platform, stale documentation is a compliance risk.
⏮️ Previous: Part 7 — Real-Time Intelligence: Kafka Streaming and Event-Driven Agent Triggers → | ⏭️ Next: Part 9 — Production-Grade Deployment: Kubernetes, Terraform, and Autonomous Scaling →
📖 Series context: In Part 7 — Kafka Streaming, we built the event-driven layer: KafkaPublishStage, consumer groups, schema evolution, and real-time agent triggers that react to transactions as they arrive. Now we turn to a question that becomes critical once the platform is running: how does anyone — developer, compliance auditor, or agent — understand what this system does and why it is built the way it is? Documentation as code answers that question systematically. In Part 9 — Kubernetes Deployment, we will take the documented, tested platform and ship it to production — where the documentation we write here becomes the specification that Terraform and Kubernetes manifests must match.
💡 Quick stats: 📚 4 documentation layers — docstrings, ADRs, data dictionary, OpenMetadata · 👥 2 audiences — humans need rationale, agents need precise schemas · 🔒 3 automated CI enforcement mechanisms — coverage checks, schema sync pre-commit hook, post-deploy catalog sync · ♻️ 0 manual update steps when OpenMetadata is the living catalog
🤖 Documentation That Machines Read
If you are a data engineer or platform architect building systems where AI agents invoke tools, process schemas, and make autonomous decisions — this section addresses a documentation failure mode most teams discover only after it has already caused an incident. By the end, you will know exactly which documentation artefacts require a machine-readable format, why your LLM planner’s tool selection accuracy depends on them, and how to derive both human and machine documentation from a single source.
Traditional documentation serves human readers. In an agentic platform, documentation as code serves machine readers too — the agents themselves.
When an agent invokes an MCP tool, it needs to understand what the tool does, what parameters it expects, and what it returns. When a LangGraph orchestrator builds a workflow, it selects agent nodes based on their described capabilities. When the PII scrubber processes a memo field, Presidio’s entity recognition models are themselves a form of machine-readable data documentation — they encode the schema of personal identifiers in natural language text.
This dual audience — humans and agents — shapes every documentation decision in this platform:
- Human documentation optimises for understandability: context, rationale, examples, and the why behind design choices
- Machine documentation optimises for precision: typed parameters, capability descriptions in structured formats, and explicit calling context that the LLM planner can parse
The platform needs both, and they must be derived from the same source where possible — two separate representations of the same truth always diverge, and in a compliance-regulated financial system, that divergence creates audit risk.
↑ Back to top · Next: Docstring Standards →
📝 Docstring Standards
Every PipelineStage and agent class follows a consistent docstring standard that answers four questions in sequence: what it does, why it exists, what it accepts, and what can go wrong. The compliance rationale is embedded in the docstring itself — not in a separate document that nobody reads.
class PIIScrubberStage(PipelineStage):
"""Detect and redact PII entities from transaction memo text.
Uses Microsoft Presidio to identify PERSON, IBAN_CODE, and ID entities
in unstructured memo text and replace them with entity type labels
(e.g., [PERSON], [IBAN_CODE]).
This stage must run before DataIngestionStage to ensure PII is not
persisted to the database in violation of GDPR Article 5(1)(c).
Args:
config: Optional configuration dictionary. Supports:
- pii_entities (list[str]): Entity types to detect.
Default: ["PERSON", "IBAN_CODE", "ID"]
- language (str): Presidio analyzer language. Default: "en"
Returns:
Tuple of (transactions, scrubbed_memos) where scrubbed_memos
contains the original memo text with PII replaced by labels.
Raises:
RuntimeError: If Presidio analyzer initialization fails.
"""The compliance rationale — “GDPR Article 5(1)(c)” — is present in the docstring itself, not just in a separate policy document. This means a developer reading the code understands the regulatory reason for the stage’s position in the pipeline without needing to consult a separate document. It also means a compliance auditor reviewing the codebase can verify that the implementation matches the stated regulatory obligation.
🔧 Agent Tool Docstrings
Agent tools have a slightly different docstring structure because they are consumed by both human developers and the MCP server’s tool registry (covered in Part 14). The tool registry presents each tool’s description to the LLM planner when it selects which tool to invoke:
def evaluate_transaction_policy(
transaction_type: str,
amount: float,
currency: str,
context: dict,
) -> PolicyDecision:
"""Evaluate whether a transaction is permitted by the governance policy.
Queries the OPA policy engine to determine whether a transaction with
the given attributes should be allowed or denied. Returns the policy
decision with reasons, suitable for audit logging.
This tool is invoked by the compliance audit agent when a transaction
requires governance evaluation. It should not be used for high-frequency
batch validation — use OPAPolicyEnforcementStage for that.
Args:
transaction_type: One of the configured TRANSACTION_TYPES values.
amount: Transaction amount in the base currency. Must be positive.
currency: ISO 4217 currency code.
context: Additional context for policy evaluation (e.g., edd_completed).
Returns:
PolicyDecision with fields: allowed (bool), reasons (list[str]),
policy_version (str).
"""The “This tool is invoked by…” sentence is critical for agent tool descriptions. It tells the MCP server’s tool registry — and any agent that discovers the tool — the intended calling context. Agents use this description to decide whether this is the right tool for a given task.
💡 Pro tip: The “invoked by” sentence in an agent tool docstring is not commentary — it is the primary signal the LLM planner uses when selecting which tool to call. A vague description causes wrong tool selection in production. A precise description with explicit calling context produces correct agent behaviour. Write tool docstrings for the LLM first, the human second.
↑ Back to top · Next: Architecture Decision Records →
🏛️ Architecture Decision Records
Architecture Decision Records (ADRs) document the why behind significant design choices — not what the code does, but why the platform is structured the way it is, and what alternatives were rejected. They are the institutional memory that prevents the same architectural debates from recurring every time a new engineer joins the team.
The platform maintains ADRs in docs/decisions/ with a consistent structure. ADR-001 documents the decision to use OPA for governance — a decision whose full reasoning is captured here so it does not need to be re-explained in code comments, onboarding sessions, or architecture review meetings:
# ADR-001: Use OPA for Policy-as-Code Governance
**Status:** Accepted
**Date:** 2024-01-10
**Deciders:** Data Platform Team
## Context
The platform processes financial transactions subject to GDPR, SOX, Basel III/IV,
and MiFID II. Compliance rules change regularly as regulatory guidance evolves.
We need a governance mechanism that can be updated without application code changes
and that produces audit-eligible decision logs.
## Decision
Use Open Policy Agent (OPA) with Rego policies for all governance decisions.
Policies are version-controlled in the `policies/` directory and deployed
independently of application code.
## Alternatives Considered
1. **Custom Python validation logic:** Rejected. Policy changes require code
changes, test runs, and deployment. Non-engineers cannot review or update policies.
2. **Database CHECK constraints:** Rejected. Cannot express contextual rules.
Schema migrations required for policy changes.
3. **AWS Lake Formation / GCP Dataplex:** Rejected. Cloud vendor lock-in.
Does not run locally for development.
## Consequences
- OPA must be running for the pipeline to function (fail-closed behaviour)
- Rego is an additional language for the team to learn
- Policy changes have their own deployment pipeline (Rego CI/CD)
- Every governance decision is logged, satisfying SOX audit requirementsADRs have three essential properties that make them worth maintaining:
- 🔒 Immutable after acceptance. When a decision is superseded, a new ADR is created with a “Supersedes ADR-XXX” reference. The old ADR is not deleted — the history of why decisions were made is as valuable as the decisions themselves, especially for regulatory audit trails.
- 🔍 Searchable alongside code. Storing ADRs as Markdown files in the repository means they appear in code search. A developer wondering why OPA was chosen over custom validation can find ADR-001 through the same search workflow they use to find production code.
- 🗑️ Capturing rejected alternatives is the highest-value section. When a new team member suggests “why don’t we use database constraints for governance?”, the ADR shows that this was considered and why it was rejected. Without the ADR, the same conversation happens again — and again. With it, the institutional decision is final.
💡 Pro tip: If your ADRs do not include an “Alternatives Considered” section with reasons for rejection, they are capturing only half the value. The rejected options are the institutional memory that prevents re-litigation. A one-paragraph “Decision” with no alternatives is a note, not a record.
↑ Back to top · Next: Data Dictionary →
📚 Data Dictionary
The data dictionary documents the staged_data table schema in a format that both humans and OpenMetadata can consume — making it the single authoritative source for column descriptions, PII classifications, access controls, and retention policies. When the dictionary and the schema diverge, a pre-commit hook rejects the commit.
# data-dictionary/staged_data.yml
table: staged_data
description: >
Processed financial transactions with PII scrubbed from memo fields.
Source of truth for compliance reporting and downstream analytics.
Governed by GDPR (data minimisation, retention), SOX (audit trail),
and MiFID II (transaction completeness).
columns:
- name: transaction_date
type: DATE
nullable: false
description: Date the transaction was initiated. ISO 8601 format.
business_name: Transaction Date
pii: false
- name: original_memo
type: TEXT
nullable: true
description: >
Original transaction memo text before PII scrubbing.
Contains personal identifiers. Access restricted to compliance team.
Retention: 7 years per SOX Section 802.
business_name: Original Transaction Description
pii: true
access_classification: restricted
retention_days: 2555
- name: scrubbed_memo
type: TEXT
nullable: true
description: >
Transaction memo text with PII replaced by entity type labels.
Safe for analytics use. Does not contain personal identifiers.
business_name: Sanitised Transaction Description
pii: false
access_classification: internal
- name: audit_metadata
type: JSONB
nullable: false
description: >
Pipeline execution context embedded in the record.
Contains batch_id, governance_decision, pii_detected, retention_days.
Used for SOX audit queries and compliance reporting.
business_name: Audit Metadata
pii: falseThis YAML format is parseable by the OpenMetadata import tool, making the data dictionary the authoritative source for the catalog entries. Changes to the database schema go through the same pull-request review process as application code — which means the dictionary cannot silently drift from what is actually deployed.
↑ Back to top · Next: OpenMetadata as Living Documentation →
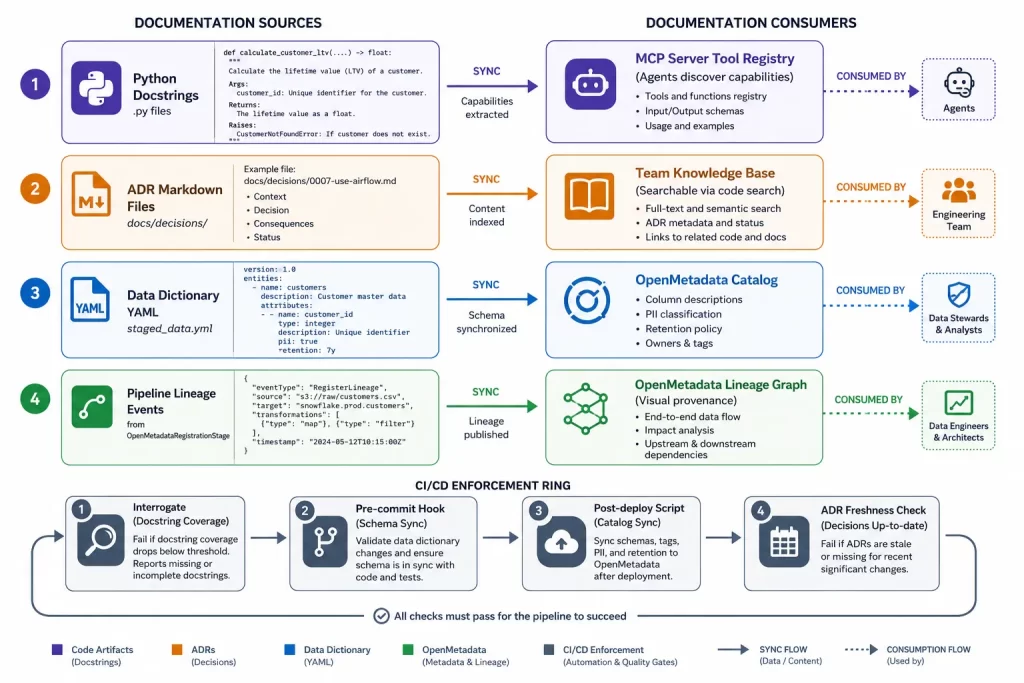
🗂️ OpenMetadata as Living Documentation
OpenMetadata serves as the platform’s operational documentation layer — the place where documentation about data assets is stored, queried, and updated automatically every time the pipeline runs. Unlike a wiki page or a README, it cannot be out of date because the platform itself is what keeps it current.
The OpenMetadataRegistrationStage registers datasets and lineage events on every pipeline execution. The data dictionary YAML seeds the catalog with column descriptions and classifications on every deployment. The result is a searchable, browsable catalog where a data analyst can:
- ✅ Find the
staged_datatable by name or by tag - ✅ Read its description and column-level documentation including PII flags
- ✅ See which pipeline stages produced it via the lineage graph
- ✅ Know which columns contain PII and what access classification applies — without reading the policy documents
- ✅ Understand the 7-year SOX retention policy without asking the compliance team
This is documentation that is continuously kept current by the platform itself — it requires no separate documentation maintenance process, no reminders to update a wiki, and no drift between what is documented and what is deployed.
↑ Back to top · Next: README Structure →
📄 README Structure
The project README is the onboarding document for every new engineer — and the first signal to an open-source contributor or technical reviewer about whether this platform is professionally maintained. It follows a structure optimised for the most common questions a new engineer asks, answered in the order they are typically asked.
# Agentic Data Platform
## What This Is
One paragraph. What problem does this platform solve?
## Quick Start
The minimum commands to get a working environment running.
Should take under 10 minutes.
## Architecture
Link to the architecture article (Part 3 of this series).
High-level diagram showing service interactions.
## Key Concepts
Brief definitions of: PipelineStage, Agent, OPA Policy, LangGraph,
MCP Server. Links to the relevant series articles for depth.
## Development Guide
How to run tests. How to add a new pipeline stage. How to update
an OPA policy. How to run the full integration suite.
## Configuration Reference
Table of all environment variables with descriptions and defaults.
This is generated from libs/common/config.py to stay current.
## Compliance and Governance
Where to find the Rego policies. What the OPA decision log looks like.
How to run the compliance test suite.The README is a navigation aid, not a reference document. Comprehensive documentation belongs in the component’s module docstrings (code), the ADR directory (architectural decisions), the data dictionary (data assets), and OpenMetadata (runtime lineage). The README’s job is to point to each of these in under two minutes — if it takes longer to orient a new engineer, the README is doing too much or too little.
↑ Back to top · Next: Keeping Documentation Current →
🔁 Keeping Documentation Current
Documentation without automated enforcement is a liability, not an asset. It creates a false sense of coverage while silently diverging from the code it describes. The platform uses three CI-enforced mechanisms to keep every documentation layer current — because documentation that depends on human discipline to stay accurate will eventually fail, and in a regulated system, that failure will surface during an audit.
- 🧪 Docstring coverage checks in CI:
interrogateorpydocstylefails the build if public classes and functions lack docstrings. This does not verify that docstrings are correct — it prevents the most common failure mode of no documentation at all. A failing build is the cheapest possible enforcement mechanism. - 📋 ADR freshness checks: A CI script verifies that no ADR is marked “Proposed” for more than 14 days without a status update. Proposed ADRs older than 14 days trigger a reviewer notification. This prevents ADRs from accumulating in a permanent “proposed” state that nobody reads.
- 🔗 Data dictionary schema sync: A pre-commit hook compares the YAML dictionary against the live database schema. If columns exist in the schema but are missing from the dictionary — or if the dictionary references columns that no longer exist — the commit is rejected. The dictionary and the schema are always in sync.
- ☁️ OpenMetadata post-deploy sync: After every deployment, a post-deploy script pushes the data dictionary YAML to OpenMetadata. The catalog reflects the latest deployed schema automatically — no manual catalog update is ever required.
↑ Back to top · Next: Frequently Asked Questions →
❓ Frequently Asked Questions
Common questions about documentation as code for agentic data platforms, answered from real-world implementation experience building regulated financial systems.
What are Architecture Decision Records (ADRs) and why do they matter for data platforms?
ADRs are short Markdown documents stored in docs/decisions/ alongside the code they describe. Each record captures a significant design decision — what was decided, why, and which alternatives were rejected with reasons. They matter for data platforms specifically because data architecture decisions (which storage engine, which governance mechanism, which retention policy) have long-lived compliance consequences. An ADR for choosing OPA over custom validation logic means a new engineer reads the record rather than re-litigating a decision the team already made with full regulatory context.
How does OpenMetadata keep data documentation automatically up to date?
Two mechanisms work together. First, the OpenMetadataRegistrationStage emits lineage events and dataset registrations to OpenMetadata on every pipeline run — so the lineage graph and quality metrics always reflect the most recent execution. Second, a post-deploy script imports the data dictionary YAML into OpenMetadata after every deployment — so column descriptions, PII flags, and retention policies always reflect the current schema. Neither mechanism requires manual intervention. The catalog is a byproduct of normal operations, not a separate maintenance task.
Why do AI agents need machine-readable documentation?
Because agent tool selection is driven by tool descriptions, not by code inspection. When the LLM planner in the MCP server decides which tool to invoke for a given task, it reads the tool’s docstring. A vague description produces wrong tool selection — the agent calls the wrong function, passes incorrect parameters, or fails to use a tool that would have been the correct choice. Machine-readable documentation (structured docstrings, typed parameters, explicit calling context like “this tool is invoked by the compliance audit agent”) directly determines agent behaviour quality in production. It is not supplementary — it is part of the system’s functional specification.
How do you prevent documentation from going stale in a fast-moving data pipeline?
Automation, not discipline. Three CI mechanisms enforce currency: (1) interrogate or pydocstyle in CI fails builds when public classes lack docstrings — eliminating the most common failure mode. (2) A pre-commit hook compares the data dictionary YAML against the live database schema and rejects commits where the two have diverged. (3) A post-deploy script syncs the dictionary to OpenMetadata after every deployment. The principle: documentation that requires human discipline to maintain will go stale within months. Documentation enforced by CI tooling stays current indefinitely.
↑ Back to top · Next: Key Takeaways →
🔑 Key Takeaways
- Documentation as code serves a dual audience — humans need context and rationale; agents need precise capability descriptions and typed schemas. Deriving both from the same source prevents the divergence that creates compliance audit risk.
- Architecture Decision Records capture the why, not the what — their highest-value section is “Alternatives Considered with reasons for rejection,” which eliminates recurring architectural debates as teams grow and change.
- The data dictionary must be machine-parseable YAML, not a Word document or wiki page — only then can it seed OpenMetadata automatically, be validated against the live schema by a pre-commit hook, and travel through version control alongside the code it describes.
- OpenMetadata is the living documentation layer — continuously updated by pipeline lineage events and post-deploy scripts, it reflects actual system state rather than the state at the last manual update, which may have been months ago.
- Agent tool docstrings directly determine LLM planner accuracy — the “invoked by” sentence tells the planner the intended calling context; vague descriptions produce wrong tool selection; precise descriptions produce correct agent behaviour in production.
- Documentation currency requires CI enforcement, not good intentions — docstring coverage checks, schema sync pre-commit hooks, ADR freshness scripts, and post-deploy catalog sync remove the human discipline dependency that causes all documentation to eventually go stale.
🙏 Thank You, Reader
Thank you for working through the documentation layer. The patterns here — docstrings with embedded compliance rationale, immutable ADRs with rejected alternatives, machine-parseable data dictionaries, and CI-enforced currency checks — are the difference between a platform that any engineer can navigate confidently and one that only its original authors understand six months after it shipped.
📫 Connect With Me
- 💼 LinkedIn: Connect with me on LinkedIn
- 💻 GitHub
⚠️ Disclaimer: The information provided on LearnWithNeeraj.com regarding Astrology, Numerology, and other topics is for educational and guidance purposes only.
Not Professional Advice: This content should not be used as a substitute for professional medical, legal, or financial advice. Always consult a certified professional for specific concerns.
Guest Authors: This site features articles by various contributors. The views and interpretations expressed are those of the individual authors and do not necessarily reflect the views of the website administrator.
Your destiny is in your hands. Use this information as a map, not a mandate.