📌 TL;DR
Before writing a single line of pipeline code, I spent significant time on architecture. The decisions made here — how stages are composed, where agents plug in, how governance is enforced, how lineage is captured — shape everything that follows. This article explains the architectural blueprint: a stage-based pipeline where agents are first-class citizens, governance is declarative and cross-cutting, and every execution leaves a complete audit trail aligned with OpenLineage.
⏮️ Previous: Engineering the Foundation: A Production-Grade Development Environment | ⏭️ Next: Synthetic Data Engineering: Teaching Your Platform What Real Data Looks Like →
Part 1 : From Scripts to Sentience: Building an Agentic Data Platform
📖 In This Article
- Starting With Why, Not How
- The TOGAF Lens
- The Stage-Based Pipeline Design
- The Stage Sequence
- Where Agents Plug In
- Governance as a Cross-Cutting Concern
- Lineage: Every Execution Leaves a Trail
- Configuration-Driven Stage Composition
- Error Handling Architecture
- Observability Baked In
- How the Architecture Evolves
- Key Takeaways
🎯 Starting With Why, Not How
A common mistake in data platform design is jumping to tool selection before understanding what architectural problems you are solving. “We need Kafka” is not an architecture. “We need event-driven ingestion so that compliance agents can react to data arrival in real time” is an architecture that happens to use Kafka.
The architectural problems this platform solves are:
- Compliance enforcement at ingestion time, not as a post-processing step that can be skipped
- Complete data lineage, captured automatically as data flows through the pipeline, not assembled manually for audits
- Agent extensibility, meaning new intelligent capabilities can be added to the pipeline without rewriting existing stages
- Operational observability, meaning the pipeline’s internal behaviour is visible to operators without access to the source code
- Separation of concerns, meaning business logic, governance policy, and infrastructure concerns can evolve independently
These five requirements produce an architecture. The tools follow.
↑ Back to top · Next: The TOGAF Lens →
🏛️ The TOGAF Lens
Before diving into code, it helps to view the platform through the TOGAF (The Open Group Architecture Framework) lens. TOGAF’s Architecture Development Method (ADM) structures a system into four interrelated architecture domains, ensuring that technology choices serve the business rather than the other way around:
- 🏢 Business Architecture defines what the platform exists to do: process financial transactions, enforce regulatory compliance, and provide auditable data provenance for regulators and internal governance teams.
- 🗄️ Data Architecture defines what data the platform manages: transaction records with financial metadata, PII that must be detected and handled according to GDPR, lineage metadata per the OpenLineage standard, and policy evaluation logs.
- ⚙️ Application Architecture defines the components that process data: the pipeline stages, the agent network, the MCP server tool registry, and the governance layer.
- 🏗️ Technology Architecture defines the infrastructure: Kafka for streaming, PostgreSQL for persistence, MinIO for object storage, OPA for policy evaluation, OpenMetadata for cataloguing.
The value of this exercise is that it surfaces the right questions in the right order. I designed the data architecture — what audit fields does every record need to carry? — before the application architecture — how do stages communicate? Skipping straight to the technology layer produces platforms that are technically sophisticated but operationally brittle.
↑ Back to top · Next: The Stage-Based Pipeline Design →
🔩 The Stage-Based Pipeline Design
The core abstraction is the PipelineStage — an abstract base class with exactly two methods that every processing step must implement:
class PipelineStage(ABC):
@abstractmethod
def execute(self, data: Any, pipeline_context: dict) -> Any:
"""Process data and return the result for the next stage."""
...
@abstractmethod
def name(self) -> str:
"""Identifier used in logs, metrics, and lineage records."""
...The interface is intentionally minimal. execute() receives the output of the previous stage and a shared context dictionary; it returns data for the next stage to consume. name() is the string that flows into every Prometheus metric label, every log line, and every OpenLineage job identifier that the stage produces. Nothing else is mandated by the contract.
This simplicity has real consequences. A new stage can be written, unit-tested in complete isolation by calling execute() directly, and inserted anywhere in the pipeline without modifying any other stage. The pipeline runner doesn’t need to understand what any stage does — it just calls execute() and passes the result to the next stage in sequence.
🗒️ The Pipeline Context
Alongside the primary data, each stage receives and can modify a pipeline_context dictionary — the pipeline’s shared notepad. It carries metadata that isn’t part of the records themselves but that downstream stages need:
# Evolves as each stage runs
pipeline_context = {
"batch_id": "batch-2024-01-15-001", # Set at pipeline start
"scrubbed_memos": [...], # Written by PIIScrubberStage
"governance_result": {"allowed": True},# Written by GovernanceStage
"lineage_registered": True, # Written by LineageRegistryStage
}Each stage reads what it needs and writes what later stages will need. The dependency is implicit in the ordering, not declared. A typed Pydantic model for the context would be safer — it would catch a misspelled key at startup rather than at runtime — and that refactor is the natural next step before a production hardening pass.
↑ Back to top · Next: The Stage Sequence →
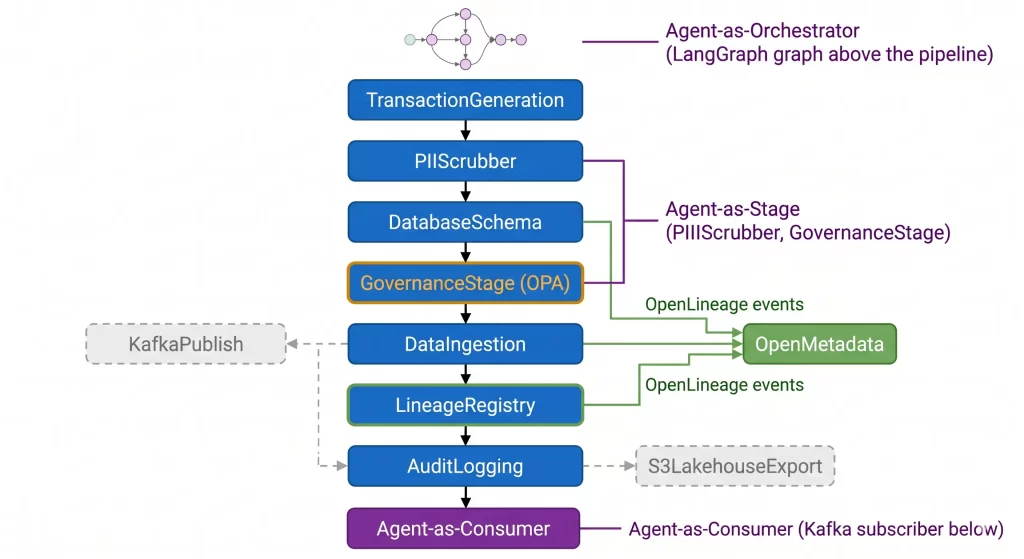
📋 The Stage Sequence
A typical pipeline execution follows this stage sequence:
TransactionGeneration
↓
PIIScrubber
↓
DatabaseSchema
↓
Governance (OPA evaluation)
↓
DataIngestion
↓
LineageRegistry
↓
AuditLogging
↓
[Optional: KafkaPublish, S3LakehouseExport, CDCTracking]ℹ️ Optional stages are controlled by environment variable toggles. The same codebase runs in minimal mode (generation → validation → ingestion) for development and full mode (all stages active) for production — no code branching required, only configuration.
↑ Back to top · Next: Where Agents Plug In →
🤖 Where Agents Plug In
Agents are not separate from the pipeline — they are embedded in it at three integration points:
🔗 Agent-as-Stage
Some agents are pipeline stages. The PIIScrubberStage wraps a PIIScrubberAgent; the GovernanceStage wraps a policy evaluation agent. These agents receive the pipeline data, apply their reasoning, and return the (possibly transformed) data back to the pipeline:
class PIIScrubberStage(PipelineStage):
def execute(self, data, pipeline_context):
transactions, _ = data
scrubbed = [self.scrubber.scrub_memo(tx.memo) for tx in transactions]
pipeline_context["scrubbed_memos"] = scrubbed
return transactions, scrubbed
def name(self):
return "PIIScrubber"The agent’s intelligence — knowing which patterns constitute PII, which NLP model to use, which replacement labels to apply — is entirely encapsulated inside the stage. From the pipeline runner’s perspective, it is just another execute() call.
🔀 Agent-as-Orchestrator
The LangGraph orchestrator sits above the pipeline. It receives queries or triggering events, coordinates multiple specialised agents through a stateful directed graph, and can invoke pipeline operations as tool calls via the MCP server. This is where complex multi-step reasoning happens — for example, detecting an anomalous transaction cluster, invoking the compliance audit agent for a ruling, and conditionally triggering the alert pipeline based on the outcome. The orchestrator is covered in depth in Part 12.
📡 Agent-as-Consumer
Some agents operate asynchronously, subscribing to Kafka topics where the pipeline publishes processed records and metadata events. A drift-monitoring agent, for example, consumes a stream of ingested records and flags statistical anomalies without blocking the pipeline’s main execution path. This pattern is particularly useful for retrospective analysis — the pipeline doesn’t need to slow down to wait for the agent’s inference.
↑ Back to top · Next: Governance as a Cross-Cutting Concern →
⚖️ Governance as a Cross-Cutting Concern
One of the most consequential architectural decisions was treating governance as a cross-cutting concern — something that applies to every stage’s output and cannot be disabled or skipped.
The implementation uses Open Policy Agent (OPA), a general-purpose policy engine that evaluates declarative Rego policies against any JSON input. “Rego” (short for Regulation Go) is OPA’s purpose-built policy language — a rule-based language designed for expressing access control and compliance logic that separates the policy definition from the application code that enforces it.
The GovernanceStage sends a structured representation of each batch to OPA and receives an allow/deny decision:
class GovernanceStage(PipelineStage):
def execute(self, data, pipeline_context):
decision = self.opa_client.evaluate(
policy_path="agentic/allow",
payload={
"identity": "pipeline",
"action": "write",
"context": {
"contains_pii": pipeline_context.get("contains_pii"),
"pii_scrubbed": pipeline_context.get("pii_scrubbed"),
"audit_logged": pipeline_context.get("audit_logged"),
}
}
)
if not decision.get("allow"):
raise GovernanceDeniedError(decision.get("reasons"))
return dataA corresponding Rego policy file defines what “allowed” means. The policy is version-controlled alongside the application code. When a regulatory requirement changes the criteria for approval, the .rego file is updated, its tests run, and the change ships. The application code above does not change. This separation of what is allowed (Rego) from how to enforce it (the stage) is what makes the platform adaptable to regulatory change without engineering risk.
↑ Back to top · Next: Lineage: Every Execution Leaves a Trail →
🔗 Lineage: Every Execution Leaves a Trail
The LineageRegistryStage captures provenance metadata for every pipeline execution. The metadata follows the OpenLineage standard — an open specification (governed by the Linux Foundation’s OpenLineage project) that defines a common format for describing data jobs, runs, and datasets, so that lineage records can be consumed by any compatible tool (OpenMetadata, Marquez, Atlan) without platform-specific integration.
An OpenLineage event has three core parts: the Job (what process ran), the Run (the specific execution of that job, with a UUID and timestamps), and the Datasets (what data was consumed and what was produced). Extended metadata is attached via Facets — typed annotations for schema, data quality metrics, column-level transformations, and ownership.
# Illustrative OpenLineage event structure
lineage_event = {
"eventType": "COMPLETE",
"job": {"namespace": "agentic-pfm", "name": "transaction_pipeline"},
"run": {"runId": str(uuid.uuid4()), "facets": {"batch_id": batch_id}},
"inputs": [{"namespace": "agentic-pfm", "name": "synthetic_generator"}],
"outputs": [{"namespace": "postgres", "name": "staged_data",
"facets": {"columnLineage": {...}}}], # maps memo → scrubbed_memo
}These events are forwarded to OpenMetadata, where they render as a visual lineage graph. For every record in the database, a compliance auditor can trace the complete journey: which stage produced it, when, and what transformations were applied along the way. This directly satisfies the data provenance requirement that drove the architecture decision.
↑ Back to top · Next: Configuration-Driven Stage Composition →
🧩 Configuration-Driven Stage Composition
Stages are not hardwired in a single Python file — they are composed from configuration. Each stage is registered with metadata that the pipeline factory reads at startup:
@dataclass
class PipelineStageMetadata:
name: str
description: str
tags: List[str] = field(default_factory=list) # e.g. ["governance", "streaming"]
requires_db: bool = False
# ...The tags field drives filtering: stages tagged ["governance"] cannot be disabled in production, while stages tagged ["streaming"] are excluded when running in batch-only mode. Adding a new stage to the platform means registering it here — not modifying the pipeline runner.
↑ Back to top · Next: Error Handling Architecture →
🛟 Error Handling Architecture
Every pipeline stage can fail. The architecture defines three explicit failure modes — this classification is part of each stage’s registered metadata:
- 🛑 Fail-fast: The stage raises an exception, the pipeline halts, and the entire batch is rejected. Used where partial completion is worse than no completion — governance evaluation, schema validation. A batch with three valid records and one that failed governance does not get partially ingested.
- ⚠️ Fail-soft: The stage logs the error, records it in the context, and returns the data unchanged so the pipeline continues. Used for optional enhancements like S3 export or CDC tracking, where a transient failure should not block primary data ingestion.
- 🔄 Retry with backoff: Used for transient external service failures — network timeouts, temporary OPA unavailability. An exponential backoff retry decorator wraps the external call, giving the service time to recover without crashing the pipeline.
When an incident occurs, operators can immediately determine from the metrics and logs which failure mode was active — essential for triage when the on-call engineer is being paged at 2 AM.
↑ Back to top · Next: Observability Baked In →
📊 Observability Baked In
Every stage emits Prometheus metrics as a side effect of execution. The labels are standardised across all stages so that dashboards and alerts can be written generically:
# Counters — increment on each stage execution
pipeline_stage_executions_total{stage="DataIngestion", status="success"}
pipeline_stage_executions_total{stage="DataIngestion", status="failed"}
# Histograms — track latency distributions
pipeline_stage_duration_seconds{stage="GovernanceEvaluation", le="1.0"}These metrics flow into Prometheus automatically. When an on-call engineer receives an alert, the Grafana dashboard immediately shows which stage failed, how long it ran, and how many records were processed — without needing to read the source code or parse logs.
↑ Back to top · Next: How the Architecture Evolves →
🔮 How the Architecture Evolves
Several planned evolution paths are built into the design from day one:
- ⚡ Streaming-first mode: The current architecture uses batch as the primary path with Kafka as an optional side-car. The design supports inverting this — Kafka-first, batch as fallback — by promoting the streaming stage to the primary execution path without changing the stage interface.
- 🌐 Distributed agents: The
LocalAgentNetwork(in-process agent calls) can be swapped forKafkaAgentNetwork(agents in separate pods) by changing an environment variable. TheAgentMessageprotocol is transport-agnostic, so the orchestration logic doesn’t change. - 🧊 Iceberg lakehouse: The S3 export stage writes to Apache Iceberg tables when
ENABLE_ICEBERG=true. This is purely additive — the PostgreSQL storage path is unaffected.
🙏 Thank You, Reader
Thank you for working through the architecture. These decisions — stage contracts, governance placement, lineage format, failure mode classification — are the load-bearing walls of everything built in subsequent articles. Understanding why each choice was made is as important as knowing what it does.
📫 Connect With Me
- 💼 LinkedIn: Connect with me on LinkedIn
- 💻 GitHub
↑ Back to top · Next: Key Takeaways →
🔑 Key Takeaways
- The
PipelineStagecontract — two abstract methods, nothing else — gives the pipeline its composability without introducing coupling between stages. - Viewing the platform through TOGAF‘s four architecture domains ensures technology choices serve the business, not the other way around.
- Governance via OPA must be a cross-cutting concern enforced in the execution path, not an advisory layer that can be bypassed.
- OpenLineage provides a standard, tool-agnostic format for lineage events; use it instead of inventing a custom provenance format.
- Three explicit failure modes (fail-fast, fail-soft, retry) should be part of every stage’s design, not an afterthought discovered during an incident.
- Configuration-driven stage composition means adding a new stage is a registration step, not a change to the pipeline runner.
Enjoyed this article?
Get notified when the next one is published.
We send one email per new article — no spam, unsubscribe any time.
⚠️ Disclaimer: The information provided on LearnWithNeeraj.com regarding Astrology, Numerology, and other topics is for educational and guidance purposes only.
Not Professional Advice: This content should not be used as a substitute for professional medical, legal, or financial advice. Always consult a certified professional for specific concerns.
Guest Authors: This site features articles by various contributors. The views and interpretations expressed are those of the individual authors and do not necessarily reflect the views of the website administrator.
Your destiny is in your hands. Use this information as a map, not a mandate.